We now stay within C code while generating large JSON objects for responses, which should be substantially faster than the previous technique, which fell back to Python for encoding.
Spam checker modules can now use a user_may_create_room_with_invites callback to inspect room creation events which include invitations to users via Matrix or other media (email, etc.).
Additionally, the ModuleApi can now inspect IP and User Agent data, as well as checking whether Rooms and MXIDs are local to the current homeserver.
These are just the highlights; please see the Upgrade Notes and Release Notes for a complete list of changes in this release.
Synapse is a Free and Open Source Software project, and we'd like to extend our thanks to everyone who contributed to this release, including aaronraimist, cvwright, govynnus, Kokokokoka, and tulir.
This week in Matrix, William tells us about the State Compressor he wrote during his internship to reduce the size of Synapse's database, and so much more. William being a former intern of the backend team, who else than his mentor Brendan could lead the interview?
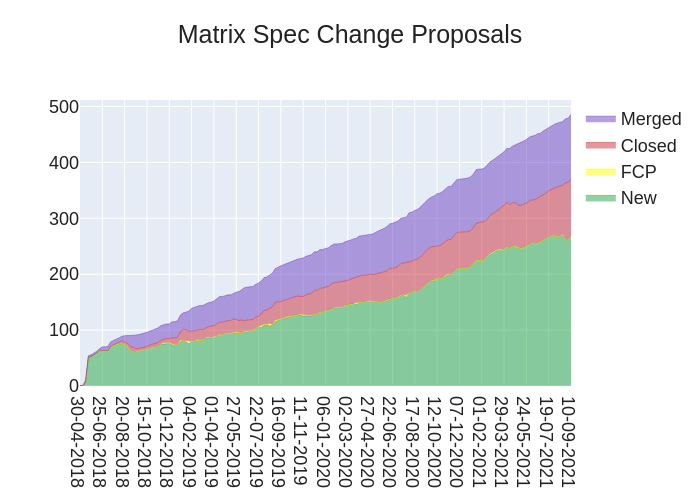
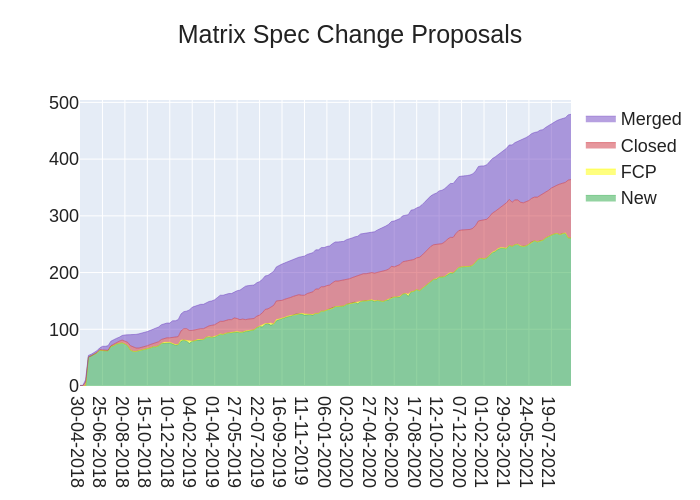
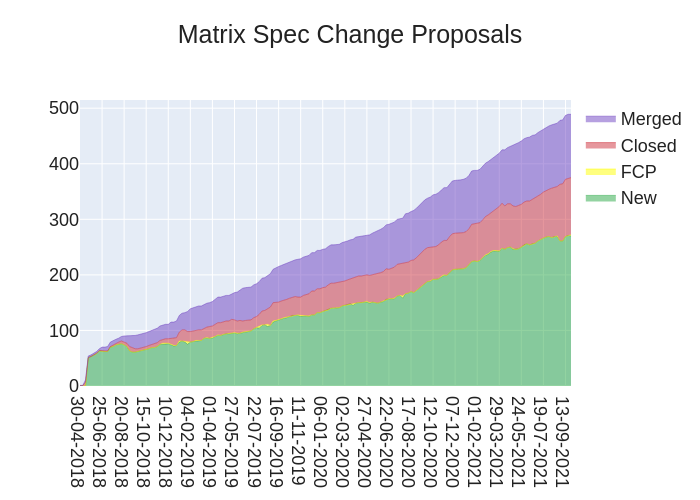
Hello! It is not-anoa here with the spec update this week, which unfortunately means no pretty graph of MSCs (sorry). I do however have some curated updates to the spec for you:
Though WIP, both are exciting steps towards much larger goals - looking forward to see how they progress! We also saw FCP finish on MSC3231: Token authenticated registration, part of Callum's GSOC project this summer - congratulations! MSC2918: Refresh tokens also finished FCP this week, making it a good time for clients to consider that access tokens might expire or appear in a different format in upcoming versions of the spec. MSC2582: Remove mimetype from EncryptedFile object was also merged to the spec - thanks Sorunome for finding the duplicated field which was duplicated!
Behind the scenes, the Spec Core Team (SCT) has been thinking about how we can release the spec as we've been talking about doing so for months. We're declaring a bit of a freeze on new things entering the spec for the time being, but that doesn't stop MSCs from completing FCP or being opened - they just might miss the v1.1 cut (sorry). Most of the work needed to release is deployment stuff rather than Matrix stuff, so the hope is is we can get it all worked out soon.
I don't have the random MSC script on hand, but I do have access to the MSC list and found WIP: MSC3030: Jump to date API endpoint. It's listed as work in progress, but is one of the MSCs I personally look forward to being accepted in time!
That's all for spec this week. I'm not sure about next week, but you might be stuck with me again. Maybe I can find those fancy graph tools in time...
Thanks a lot not-anoa, that was a great spec update!
Lots of work in preparation for Synapse 1.44 which is due out next week. Notably, we've found a few small regressions in rc1, so expect another release candidate on Monday followed by a formal release on Tuesday or Wednesday.
I look forward to telling you all about that, and our plans for Q4, next week. 🙂
Now that's some teasing! I can't wait for next week!
Hey folks, it's been a while since we released changes to the Slack bridge but here we are on our next RC. This one includes a few new things, most notably:
The bridge now automatically invites users to private rooms if there is a message and they are not joined. (#613)
Update bridge to matrix-appservice-bridge 3.1.0 (#614)
Also, a PSA: If you were struggling to bridge your rooms to matrix while using the matrix.org bridge, this should now be fixed. An update made to the Slack APIs silently broke the oauth flow, which has since been fixed. This was a misconfiguration-gone-unnoticed in our Slack app configuration, so self hosters don't need to upgrade. The details are in https://github.com/matrix-org/matrix-appservice-slack/issues/617#issuecomment-932047990
While I am a bit busy at the moment, Nheko is getting a lot of valuable smaller contributions:
Updated the emoji pickers to Unicode 14, so that you can properly troll people.
Pasting images should now work properly again on Windows and macOS, including pasting SVGs!
The help and version command line parameters now work properly, even if an instance of Nheko is already running.
There has also been a lot of progress on the translations! We just cracked 50% translated, but since that includes a lot of languages with only a few percent, this is actually much more than it sounds! We actually have 8 languages with over 90% translations now. If you speak one of the languages at 70% or so, any help translating the remaining bits is very much appreciated. You can easily translate without an account here: https://weblate.nheko.im/projects/nheko/nheko-master/#translations If you want to translate without having to rely on the upvote mechanism, feel free to ask for translation permissions directly in #nheko:nheko.im. That is also the right room to ask questions about the translation process or translations themselves.
Nheko is also participating at Hacktoberfest this year. Translations done using the webinterface won't get counted for that though, you would need to submit a pull request manually for that. If you always felt like contributing to Nheko would be fun, but you had no reason to, now you can do it to let someone plant a tree for you (or get a T-shirt)!
Hydrogen saw a few bug fixes (0.2.14, 0.2.15 and 0.2.16) this week again, and also gained the possibility to recover from low-storage scenarios where the browser would clear indexedDB.
One of the bugs fixed might have caused a timeline corruption, so when you get the 0.2.16 update the history cache will be cleared and you'll notice a bit of delay as you do an initial sync again.
Aside from working on Hydrogen as a standalone app, I'm also making it easier to embedded in other projects. More info to come on that!
We've also had a priority planning this week, which spawned an updated backlog. Have a look if you're interested what can be expected next (although be aware that the backlog has proven volatile in the past 🙂).
Hydrogen embedded! I'm looking forward to that. Great work Bruno!
After 4 years, matrix-email-bot finally got an update. Now at v2, the bot has been rewritten using TypeScript and matrix-bot-sdk (farewell, js-sdk from 2017). It still requires manual setup and the behaviour overall should be the same as before, though the amount of testing is somewhat minimal - please complain in #email:t2bot.io if something goes wrong.
The bot also now supports encrypted rooms out of the box, including on the t2bot.io instance. Check out t2bot.io/emailbot for information on how to get the bot set up in your room.
An (unofficial) Matrix server by and for the Newgrounds community.
This is a Matrix server with membership restricted to Newgrounds Supporters. Newgrounds is an independent arts & entertainment site that has been around for over 20 years, and I felt that its spirit of independence is a perfect match with the openness of Matrix!
The most notable feature of the server is comment rooms for Newgrounds submissions. Unlike other content-sharing sites, Newgrounds submissions don't have comment sections, but review sections, which let you post a single comment (and optional rating) for a submission. This encourages reviews to be focused on providing constructive feedback instead of being a place for off-topic discussions. With that said, open comment systems are nice too, so this Matrix server provides it! Simply visit #portal_view_SUBMISSION_ID:ngmvs.one to view!
These comment rooms are world-visible, but (at least for the time being) only Newgrounds Supporters may join these rooms & post comments in them.
To help along with this, I made a Firefox extension to make joining these rooms a breeze: NG MVSX. Simply view a Newgrounds submission page, and click on the icon that appears in your URL bar!
Code for all components is open-sourced on GitLab.
This is all very new, so things might break! If they do, tell me in #ngmvs-public-discussion:ngmvs.one
Hi folks, I've been let loose on more spec things: This time I'm looking at synthetic events. The goal with this proposal is to give appservices more visibility over the innards and actions of a homeserver. When a user registers, we want an appservice to know (perhaps to send them a little greeting, or to provision some resources) or perhaps you want to clear up bridge resources when the user deactivates their account.
The hope with this proposal is that it's going to set the foundations for services to be able to hook into and provide richer functionality based upon user actions outside of rooms. It might sound a little dry right now, but eventually I'm hoping this can be extended in lots of ways and potentially do away with per-implementation modules, instead writing services that work with all homeservers.
Please give the proposal some love/feedback :)
When asked if that was a specification change he drafted because of limitations faced when trying to implement a bridge, he said:
Yeah, so it's something I've been plotting for a while, but internally we wanted the ability to "act" based upon signups to a homeserver i.e. sending a welcome. In the past this has been implemented client-side in Element, but that has obvious caveats.
The traditional response has usually been to write a Synapse module, but I wanted to do something that could be used on other homeserver implementations and also not have to have it co-located with the homeserver, so the natural home for this kind of logic was appservices.
There are other things there too like logouts / deactivations which are good for erasing data on a service too. Generally I'm hoping it can be extended further once it's stable, for other use cases too
Here's your weekly spec update! The heart of Matrix is the specification - and this is modified by Matrix Spec Change (MSC) proposals. Learn more about how the process works at https://spec.matrix.org/unstable/proposals.
MSC3401 (Native Group Voip Signalling) has been receiving positive feedback over the course of the week. The MSC spells out how one would go about implementing native, decentralised group voice and video calls over Matrix without the need for a third-party service. This is the next step forward after the full-mesh group signalling work, as demoed in previous editions of TWIM, lands. Quite exciting stuff!
Otherwise there was another Spec Core Team retro this week. Discussion focused mainly on how to handle event types that not every implementation using Matrix may need (think pinned messages and how that might not be very useful for IoT networks...). Watch this space!
This is actually already implemented and enabled by default in Synapse, believe it or not. But no clients have support for it yet (there is an outstanding matrix-react-sdk PR...).
This is a pretty cool feature in my opinion, any client want to be the first?
MSC3401 looks like there's a lot of work going on on the native VoIP side. I can't wait to see what the future holds!
This week we released Synapse 1.43! This mainly contains internal changes, including those in preparation for Spaces leaving beta, but it's worth calling out that this version of Synapse now uses the MSC3244: room version capabilities API to ask clients to prefer room version 9 when creating restricted rooms.
Support for room version 9 was introduced in Synapse 1.42, so we'd strongly encourage administrators to upgrade.
Perhaps more notably for Synapse developers, we've spent quite a lot of time over the past few weeks improving the SyTest suite of integration tests. Several of the tests had race conditions which would cause them to occasionally fail when testing a multi-worker deployment of Synapse. These flakey tests have plagued our continuous integration pipelines, and are finally being fixed.
The long term plan is still to transition to Complement (written in Go) and away from SyTest (written in Perl), but we still need to ensure that SyTest is reliable in the meantime.
etke.cc now offers hosting options (and some more stuff)
Hi there,
Didn't post updates about the etke.cc service for a while. If somebody not familiar - we setup and maintain matrix servers (based on awesome spantaleev/matrix-docker-ansible-deploy)... and setup VPN... and DNS recursive resolver, and... AND!!!! Provide hosting, yes. So, starting today that's available for everyone (we offer it for some time in "well, you know, we don't provide hosting, but if you want it so hard..." way and it works good)
Even with that update (literally the most requested thing, was in every third order we got), provided hosting considered as your own server, the only difference that you don't pay hosting provider directly, but through us. So, you get root access to the server and we treat it as any other customer's infrastructure
Join #announcements:etke.cc room and say hello in #discussion:etke.cc
Heisenbridge is a bouncer-style Matrix IRC bridge.
Release v1.2.0 🥳
Message formatting (from HTML to text) has been drastically improved
CTCP replies are now shown correctly but still ignored
Mentions/pills always honor room nick
Plumb notices don't loop around anymore
Self replies don't prefix with own nick
Single line truncation works when max lines is 1
Multiple fixes to displaynames or messages containing control characters leaking to IRC
New dependency: mautrix-python
Minimum Python version requirement has been bumped to 3.7
I've also started releasing source archives as GitHub releases for distribution packagers and the project is published to PyPI to have more installation options.
What improvements did hifi bring to the formatting you may ask? I asked, and hifi answered:
the fallbacks are inconsistent and usually are markdown which is a lie 😅
replies and mentions are completely all over the place in the fallback in addition to being markdown
the unformatted html is now something in between and doesn't do code blocks at all because those ticks are just noise on irc
it tries to look like more that you pasted long text rather than sending markdown
That's very considerate for IRC user, thanks hifi!
After 2+ years of development, Quaternion makes a leap from 0.0.9.4 all the way to 0.0.95. The release notes list some key improvements: reactions, Markdown, revamped timeline, user profile dialog and a lot of other things. It’s the same small and fast client that blends nicely into your desktop environment, it just got much better. Go and get it!
We’re testing & polishing Spaces, releasing them out of beta in the upcoming release cycle next week!
On iOS
We’re anticipating some performance issues on a very small number of accounts which participate in a very large number of rooms. After trying the next release, if this affects you, please let us know as it’ll help inform whether we cut an off-cycle hotfix or prep changes for the next release.
iOS doesn’t support pagination in the Space Summary API yet, so will only return the first 50 rooms in large Spaces when browsing. Support for this is planned for the following release.
Fixing bugs and cosmetic issues with our Threads feature, currently in Labs.
Cross-signing bug fixes.
This week we Ran our first community testing session on 1.8.6 with members of the community. We were very pleased with how this went and intend to continue the sessions. You can help making Element even better by participating in our fortnightly testing sessions. Join #element-community-testing:matrix.org, and learn how to make the most useful feedback
A little synadm release went out this week. Thanks a lot to @govynnus for contributing "Registration token management", it's available as a new subcommand regtok. Also some tiny improvements here and there were brought in to make admin experience even more convenient.
Ansible Contributor Summit 2021.09 is happening next week! It will be held over 2 days, on Tuesday September 28 and Friday October 1, from 13:00-21:00 UTC, and will be held on the Matrix platform.
The Ansible Community has recently adopted Matrix as an official chat platform and this is our first Matrix-powered conference. Feedback welcome! You will need a Matrix account to participate in the conversations. For more information, please see Communication - Real-time chat and the Ansible Community Matrix FAQ.
there's a mix of stuff going on to try out, we have hack sessions on Tues that may use the embedded Jitsi etc, and talks on Friday that will be more presenter/spectator
It's exciting to see an organisation holding an online conference on Matrix!
Adds further static type hints to various modules.
We've also spent quite a lot of time on SyTest, our integration test suite. In particular, many of the tests made assumptions about event processing which were not correct when targeting a multi-worker Synapse deployment. These flakey tests have plagued our continuous integration pipelines, and are finally being fixed.
These are just the highlights; please see the Release Notes for a complete list of changes in this release.
Synapse is a Free and Open Source Software project, and we'd like to extend our thanks to everyone who contributed to this release, including AndrewFerr, BramvdnHeuvel, and cuttingedge1109.
Here's your weekly spec update! The heart of Matrix is the specification - and this is modified by Matrix Spec Change (MSC) proposals. Learn more about how the process works at https://spec.matrix.org/unstable/proposals.
If MSC2918 above is giving you feelings of déjà vu, don't worry. It already had FCP proposed, but due to a resolved concern being incorrectly processed by mscbot on github, a new FCP proposal was carried out.
In other news, MSC3381 (Polls - mk II) receive a fair amount of attention this week. It implements inline polls via a new m.poll type and makes use of the concept of extensible events. Do check it out if you're interested in voting through means other than message reactions!
Otherwise Alexandre Franke and myself will be looking at cleaning up the CI of the matrix-org/matrix-doc repo next week, as well as continue to move the infrastructure for the new spec release forwards.
This one is entirely new to me, and has some slight overlap with some work for MSC2762: Allowing widgets to send/receive events, where we were thinking about how a widget could act as a calendar using Matrix rooms and events as a calendar backend.
The Synapse team is busy gearing up for 1.43.0 next week, which will make room version 9 the default for newly created restricted rooms, among other things.
We've also been doing quite a lot of work on Sydent. Notably, last week's 2.4.0 release introduced a few regressions which have been resolved in subsequent point releases. The one-shot case folding migration script for Sydent is still performing unexpectedly slowly; look for that to be resolved soon.
As the end of the year approaches, now is a good time to ensure you're ready for the deprecation of PostgreSQL 9.6 (November) and Python 3.6 (December). Do you have plans to upgrade to Pg 10 and Py 3.7 or newer? If not, there's no time like the present! 🗓
Lastly, Hacktoberfest 2021 is less than two weeks away! Many Matrix projects intend to participate, including Synapse.
With rooms version 9 as the default, it feels like Spaces are trying hard to escape beta!
And yet again more Kubernetes Helm Chart updates this week, with element-web being bumped first to 1.8.4 and then 1.8.5. More improvements for the new ingress object in K8s 1.19 also landed.
mautrix-hangouts has turned into mautrix-googlechat. It's still in alpha stage, but text messages work in both directions, media from google chat works and threads from google chat are bridged as replies.
Released 0.2.9 & 0.2.10 this week with the main thing being improvements in preventing scroll jumps when resizing or loading more content in the timeline. Not 100% of scroll jumps will be solved with this release, but it should be improved a lot. Please report any issues you may encounter in this area! There were also a few bugs fixed, see the linked release notes. Try it out at hydrogen.element.io!
Beeper is a unified chat app built on top of Matrix. We've created 10+ open source Matrix bridges and integrated them into an easy to use all-in-one service which does not require setting up your own homeserver. You can learn more at beeper.com.
We've been hard at work for the last few weeks and have a number of updates we'd like to share across all our clients and bridges.
New verification flow for Desktop, Android, and iOS! Logging in and verifying your session is now super easy to do. This is extra important for Beeper because we enable secure backup by default and require all users to set up a security key.
Added the ability to view your rooms using our Smart Inbox that places the most important messages at the top, or with Classic which leaves the room in a reverse chronological order.
You can now select network by network which messages should appear in your inbox using our Inbox Filtering feature
We now have beta support for Custom CSS theming! Check out some of the themes that have already been made by the community. https://gitlab.com/beeper/beeper-themes
Previously we only supported DMs for Discord out of the box, but now you can pick and choose which Discord servers to sync into Beeper
Redesigned room list: we started a redesign of our Android app and adopted the Material design language.
Integrated Android SMS bridge: Our previous Android Messages bridge was built on a shakey puppeteer foundation, so we rewrote it. Our new Android SMS uses native APIs to send/receive SMS. RCS remains elusively out of our grasp for now. We open sourced our bridge at https://gitlab.com/beeper/android-sms
We are hiring! Come join many other Matrix community members who have joined the Beeper team including @tulir:maunium.net, @annie:beeper.com, @kilian:beeper.com, @spiritcroc:beeper.com and @sumner:beeper.com (who replied to our last TWIM job post and got a job at Beeper within a week!)
We are hiring senior iOS, Android developers and a DevOps/SRE (preferably in North/South America timezone)
Nheko got a lot more colorful this week. red_sky (nheko.im) and LorenDB finished up the jdenticon support. This means instead of the first character of a users display name, you now have the option to see a colorful avatar for users without an explicit avatar. You may have seen something similar on Github and other platforms. Currently this needs the qt-jdenticon plugin, which is a bit troublesome to install correctly, but we should improve that in the near future.
Prezu added a homeserver entry field to the room directory, making it much more useful (no history yet though). Thulinma added a /goto command to navigate to specific events or room and fixed scrolling to a specific event (in the past it only approximately scrolled to the right location). Symphorien added the Alt+A shortcut to navigate between rooms with active mentions and notifications. Additionally Priit completed the Estonian translation.
Additionally we released a security fix on Monday (together with a few other clients). We only released a fix for the master branch in Nheko instead of also the latest stable release. This confused a few people, but I hope my explanations made sense. The gist of it is:
On the master branch the local homeserver admin could force Nheko to forget which identity keys it saw for a user and as such insert a new device with the same device id, but attacker controlled identity keys and request old encryption keys from Nheko. In Nheko's case we had some protections against that, but if the server sent a device_list.left event for that user, Nheko would delete those protections. From our understanding this could not be abused over federation.
On 0.8.2 this can also be abused, but 0.8.2 does not implement key sharing completely. It can only forward the currently in use encryption key, not historical ones. As such the impact in our opinion was too limited to release a security fix. 0.8.2 does not allow you to send encrypted messages only to verified devices as such the homeserver admin could always insert just a different device to get access to new encrypted messages. Because of that we have a big warning in the README and when enabling encryption in 0.8.2, that one should not rely on the security of the E2EE implementation in it. We are aiming to have stable and secure E2EE in the next release (and so far it is looking good), but if you are using 0.8.2 I can only repeat, that it won't protect you from an attacker even without the disclosed security issue.
I hope this clears up some of the confusion. Feel free to visit us in #nheko:nheko.im and tell me, that I am wrong.
This week saw two releases of libolm, a library that implements olm, megolm, and some other Matrix-related encryption functions. The main changes in version 3.2.5 are new functions for getting error codes rather than error strings so that implementations don't need to rely on string parsing to decode errors, and added support for fallback keys in the Android and iOS bindings. There were also improvements in error handling in the unpickling functions, and the shared library no longer exports certain private symbols, which caused problems when those same symbols were exported by other libraries. The initial implementation of this last change caused build failures in some environments, so version 3.2.6 was released to fix this.
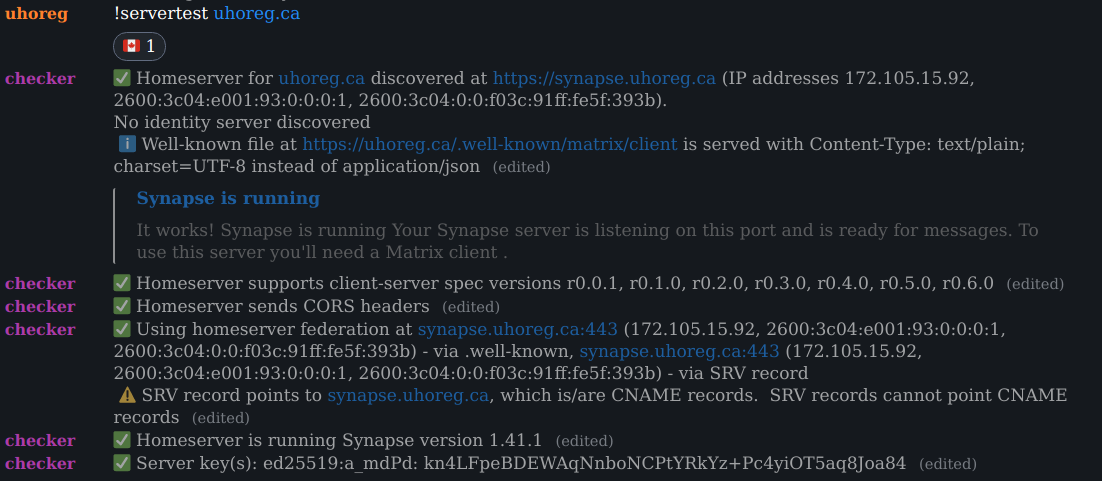
The Polyjuice project wades further into bad pun territory with a new project: Polyjuice Draughts, a set of checkers to verify that a homeserver is set up correctly and is accessible for clients and federation. It is similar in goal to the Matrix Federation Tester, but also checks client connections. It can either be run from the command line, or it can be used in a Matrix room, thanks to Igor, by sending a message of the form !servertest <servername> in a room that has an appropriately-configured bot in it. There is currently a bot in #synapse:matrix.org that can be used.
As you can see from the screenshot, my server isn't quite set up correctly, and I should fix it some day...
Polyjuice Client 0.4.3 has been released. This release adds functions for getting room membership (thanks to multi prise) and checking the server spec versions, along with some bug fixes.
I have converted the script for auto updating the Element-web instance to latest version from Gist to the full Git repo MurzNN/element-web-update and added support for .env file to set desired variables.
This is a bash script that checks the new released version of Element from official Github repo and if it differs from installed - updates the local files with deleting old version (to cleanup old files) and unpacking new one, but with keeping the config files by mask config*.json.
You can put it to your crontab.daily and got an always fresh Element with forgetting about manual update routine.
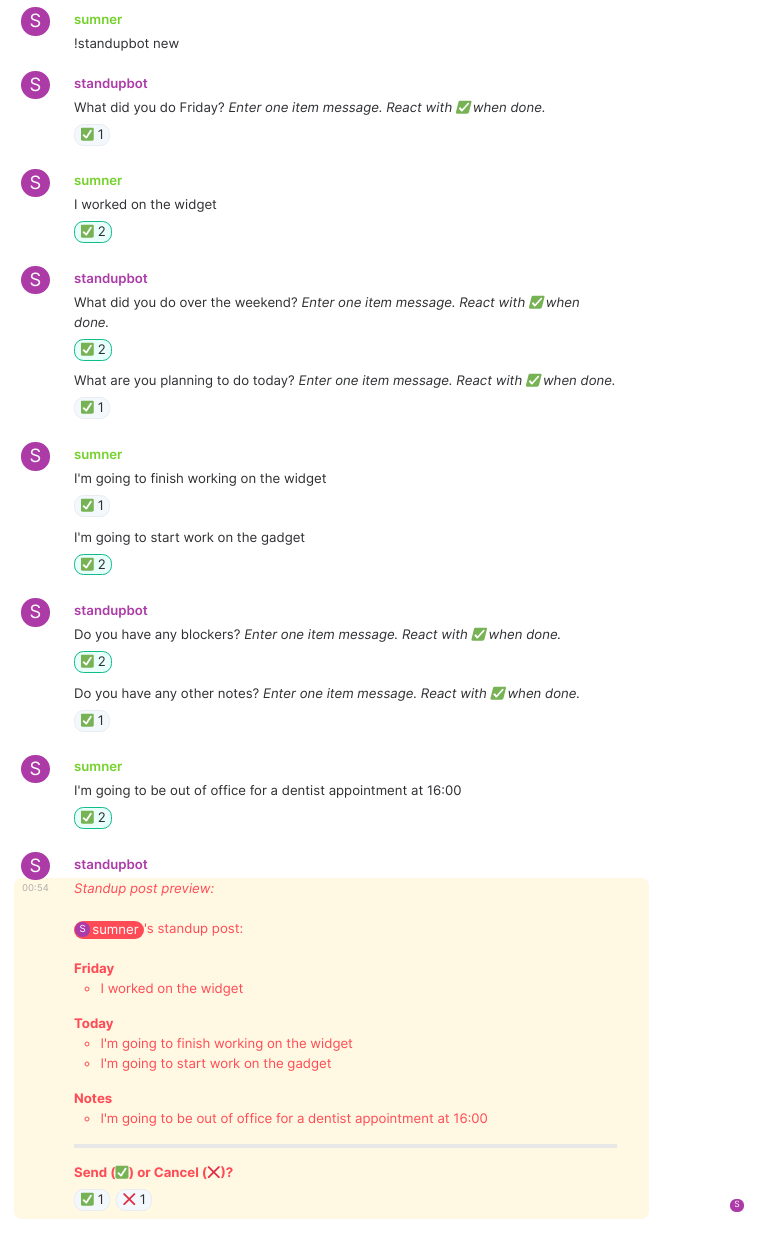
I created a bot to assist with sending standup posts to a room. It reminds you to write a standup post, and then asks you what you did the previous day, what you intend to do today, if you have any blockers, and if you have any other notes. Then it posts a nicely formatted standup post to a room which you can configure.
Are you in Berlin 🐻🇩🇪? Why not join us on Tuesday evening at 7:30 PM for a beer or two while chatting about Matrix development and hosting. We're going to meet at Schoenbrunn. This is a small 3G (self-tests are ok) event in an outdoor beer garden.
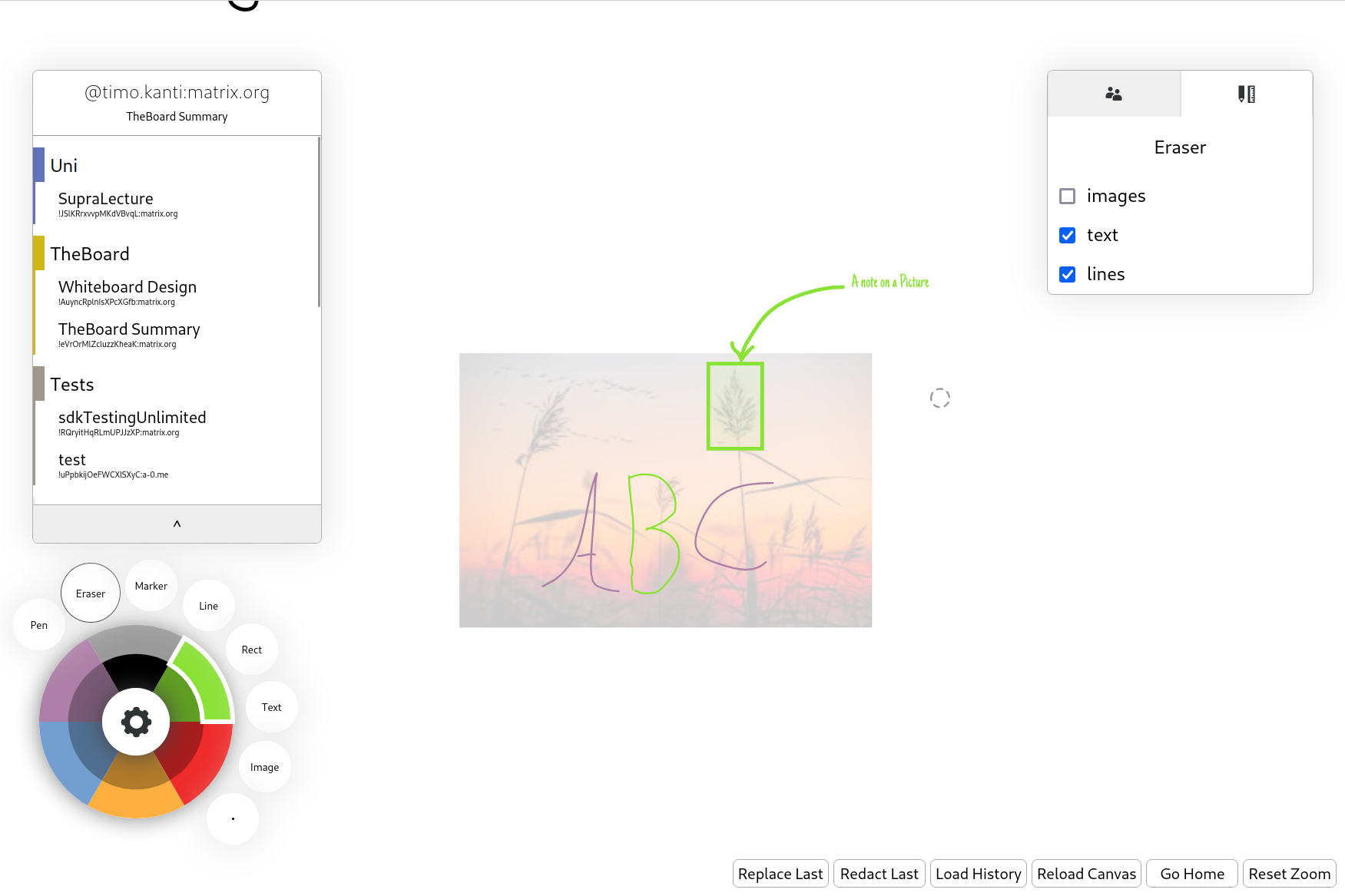
I am super happy to finally give you another update on TheBoard, due to holidays during the last weeks I had less time to work on TheBoard. But now there still accumulated enough changes for a little Update:
I experimented what technologies I could use for the still required GUI elements. A new User List was implemented using Vue.js. Vue seemed to be a little overkill for the kind of GUI required in the case of TheBoard. So I re-implemented the user list with react-no-js.
I am happy with react-no-js and it is used for a user list plus a tool settings menu on the right hand side of the canvas.
The tool panel in particular opens up a lot of possibilities. The eraser already makes use of it by giving the option to only delete specific item types (Image, stroke or text). This can be very handy if you want to delete strokes drawn on top of an image without deleting the image as well. What can be deleted is highlighted by a new filter system which allows to make any modification to objects selected by a filter function (see the attached image)
Other small changes:
Animated camera movement (for a upcoming "follow other user" feature) currently used for the Go Home Button
Opening a board now loads at the last edited location
The touchscreen navigation (zoom/pan) was re-implemented and should now work much better
The Board is very exciting! I could see in the planned use cases that Timo already intends to make a widget out of it. It would be very useful for real-time collaboration, but that's not all! When asked if a standalone app will come, Timo confirmed:
Indeed. I wasn't thinking about a builtin home-server yet. But a standalone app is still planned because I want the app to be able to manage different boards. Therefore I need to be able to control room creation and listing rooms. It should basically feel like onenote if you intend to use it like that.
@s7evink The game is called AAGRINDER, hosted at aagrinder.xyz, the code is here, the bridge implementation is here, wiki is here. The game is a text-based sandbox multiplayer browser game that I (Maze) have been building for the past 3 years. Built from nothing, no game engine. It generates an infinite procedural terrain to venture in. The integrated chatbox is nothing special but it's really nice to have it bridged to Matrix now, it's less lonely when playing alone. The appservice bridge creates users matching player name and color. Display names from Matrix are presented in the same color as in Element.
Hopefully you're able to extract some useful information out of this ^^
I love the retro vibe of the game, it's really cool!
Third Room is an experimental metaverse client I've been working on for the past couple weeks. It combines three.js and Matrix to create 3D voice chat rooms where you embody an avatar.
There's a lot more info in my talk from last night at the Open Metaverse Interoperability Demo Night (my talk starts at 37:43)
Beeper mentioned they have several positions open, and Element is also talents hungry. I’m particularly ecstatic to see that developing skills around Matrix can get people jobs. Of course I encourage strongly people to experiment with the protocol and use it in all sorts of crazy ways!
Today we are disclosing a critical security issue affecting multiple Matrix clients and libraries including Element (Web/Desktop/Android), FluffyChat, Nheko, Cinny, and SchildiChat. Element on iOS is not affected.
Specifically, in certain circumstances it may be possible to trick vulnerable clients into disclosing encryption keys for messages previously sent by that client to user accounts later compromised by an attacker.
Exploiting this vulnerability to read encrypted messages requires gaining control over the recipient’s account. This requires either compromising their credentials directly or compromising their homeserver.
Thus, the greatest risk is to users who are in encrypted rooms containing malicious servers. Admins of malicious servers could attempt to impersonate their users' devices in order to spy on messages sent by vulnerable clients in that room.
This is not a vulnerability in the Matrix or Olm/Megolm protocols, nor the libolm implementation. It is an implementation bug in certain Matrix clients and SDKs which support end-to-end encryption (“E2EE”).
We have no evidence of the vulnerability being exploited in the wild.
This issue was discovered during an internal audit by Denis Kasak, a security researcher at Element.
Patched versions of affected clients are available now; please upgrade as soon as possible — we apologise sincerely for the inconvenience. If you are unable to upgrade, consider keeping vulnerable clients offline until you can. If vulnerable clients are offline, they cannot be tricked into disclosing keys. They may safely return online once updated.
Unfortunately, it is difficult or impossible to retroactively identify instances of this attack with standard logging levels present on both clients and servers. However, as the attack requires account compromise, homeserver administrators may wish to review their authentication logs for any indications of inappropriate access.
Similarly, users should review the list of devices connected to their account with an eye toward missing, untrusted, or non-functioning devices. Because an attacker must impersonate an existing or historical device, exploiting this vulnerability would either break an existing login on the user’s account, or a historical device would be re-added and flagged as untrusted.
Lastly, if you have previously verified the users / devices in a room, you would witness the safety shield on the room turn red during the attack, indicating the presence of an untrusted and potentially malicious device.
Given the severity of this issue, Element attempted to review all known encryption-capable Matrix clients and libraries so that patches could be prepared prior to public disclosure.
fractal-next is not vulnerable due to depending on a recent enough commit.
weechat-matrix-rs, a rewrite of the original weechat-matrix script, had no tagged releases, but some commits did depend on vulnerable versions of the matrix-rust-sdk. Users should ensure to update to the latest master of weechat-matrix-rs, presently 2b093a7.
Matrix supports the concept of “key sharing”, letting a Matrix client which lacks the keys to decrypt a message request those keys from that user's other devices or the original sender's device.
This was a feature added in 2016 in order to address edge cases where a newly logged-in device might not have the necessary keys to decrypt historical messages. Specifically, if other devices in the room are unaware of the new device due to a network partition, they have no way to encrypt for it—meaning that the only way the new device will be able to decrypt history is if the recipient's other devices share the necessary keys with it.
Other situations where key sharing is desirable include when the recipient hasn't backed up their keys (either online or offline) and needs them to decrypt history on a new login, or when facing implementation bugs which prevent clients from sending keys correctly. Requesting keys from a user's other devices sidesteps these issues.
Key sharing is described here in the Matrix E2EE Implementation Guide, which contains the following paragraph:
In order to securely implement key sharing, clients must not reply to every key request they receive. The recommended strategy is to share the keys automatically only to verified devices of the same user.
This is the approach taken in the original implementation in matrix-js-sdk, as used in Element Web and others, with the extension of also letting the sending device service keyshare requests from recipient devices. Unfortunately, the implementation did not sufficiently verify the identity of the device requesting the keyshare, meaning that a compromised account can impersonate the device requesting the keys, creating this vulnerability.
This is not a protocol or specification bug, but an implementation bug which was then unfortunately replicated in other independent implementations.
While we believe we have identified and contacted all affected E2EE client implementations: if your client implements key sharing requests, we strongly recommend you check that you cryptographically verify the identity of the device which originated the key sharing request.
The fact that this vulnerability was independently introduced so many times is a clear signal that the current wording in the Matrix Spec and the E2EE Implementation Guide is insufficient. We will thoroughly review the related documentation and revise it with clear guidelines on safely implementing key sharing.
Going further, we will also consider whether key sharing is still a necessary part of the Matrix protocol. If it is not, we will remove it. As discussed above, key sharing was originally introduced to make E2EE more reliable while we were ironing out its many edge cases and failure modes. Meanwhile, implementations have become much more robust, to the point that we may be able to go without key sharing completely. We will also consider changing how we present situations in which you cannot decrypt messages because the original sender was not aware of your presence. For example, undecryptable messages could be filed in a separate conversation thread, or those messages could require that keys are shared manually, effectively turning a bug into a feature.
We will also accelerate our work on matrix-rust-sdk as a portable reference implementation of the Matrix protocol, avoiding the implicit requirement that each independent library must necessarily reimplement this logic on its own. This will have the effect of reducing attack surface and simplifying audits for software which chooses to use matrix-rust-sdk.
Finally, we apologise to the wider Matrix community for the inconvenience and disruption of this issue. While Element discovered this vulnerability during an internal audit of E2EE implementations, we will be funding an independent end-to-end audit of the reference Matrix E2EE implementations (not just Olm + libolm) in the near future to help mitigate the risk from any future vulnerabilities. The results of this audit will be made publicly available.
Ultimately, Element took two weeks from initial discovery to completing an audit of all known, public E2EE implementations. It took a further week to coordinate disclosure, culminating in today's announcement.
Monday, 23rd August — Discovery that Element Web is exploitable.
Thursday, 26th August — Determination that Element Android is exploitable with a modified attack.
Wednesday, 1 September — Determination that Element iOS fails safe in the presence of device changes.
Friday, 3 September — Determination that FluffyChat and Nheko are exploitable.
Tuesday, 7th September — Audit of Matrix clients and libraries complete.
A critical security vulnerability impacting several popular Matrix clients and libraries was recently discovered. A coordinated security release of the affected components will be happening in the afternoon (from an UTC perspective) of Monday, Sept 13th.
We will be reaching out to downstream packagers to ensure they can prepare patched versions of affected packages at the time of the release. The details of the vulnerability will be disclosed in a blog post on the day of the release. There is so far no evidence of the vulnerability being exploited in the wild.
Please be prepared to upgrade as soon as the patched versions are released.
Thank you for your patience while we work to resolve this issue.
As just blogged there is an important security fix coming for several Matrix clients. More news, and patched versions will be announced on Monday. Though there is no evidence this vulnerability has been exploited, please be ready to upgrade on Monday.
Here's your weekly spec update! The heart of Matrix is the specification - and this is modified by Matrix Spec Change (MSC) proposals. Learn more about how the process works at https://spec.matrix.org/unstable/proposals.
I'm actually surprised myself that this wasn't part of the spec already! Looks like it would be a nice to-do to get this implemented and then checked off by approvers. Anyone want to submit some PRs to HS and AS implementations? 🙂
Dimension, an integration manager alternative for Element, got a refresh from @TimeWalker to bring the project up to modern day standards. Please give it a go if you've been running Dimension, and report bugs if there's problems! While I haven't personally had time to maintain it as much as I'd like, it's great to see people taking on 3 year old bad code and fixing it 😄
For TWIM readers, Dimension is an "integration manager" that replaces the default one shipped with Element. It's not entirely mobile-ready yet, but does give a user interface for managing various bots, bridges, and widgets. In practice, an integration manager isn't needed as most bots and bridges (and even widgets) can be set up without an integrations manager, like all of https://t2bot.io/ (ironically, given Dimension was originally targeted at t2bot.io). People do still use it though to configure self-hosted platforms with their very own Element, Synapse, bridges, and bots.
While I still probably won't have much time personally to maintain it, PRs are certainly accepted. Dimension is a bit complex to work within and test, but people in #dimension:t2bot.io should be able to help out.
Synapse 1.42.0 is out now! This release includes support for Room Version 9, which fixes an issue with Version 8's support for restricted rooms. We also implement a bunch of new MSCs (including MSC3231: Token authenticated registration by Callum Brown as part of his Google Summer of Code project), improve efficiency, and sidestep a longstanding issue with users getting stuck in unsupported room versions. Read the announcement for details!
This Sydent release also includes support for Jinja2 templating, a complete overhaul of our CI/CD pipeline, and a comprehensive update to the codebase to follow modern Python practices including the addition of mypy type hints throughout.
Lastly, we'd like to welcome Shay to the Backend Team at Element. Her work as an Outreachy intern paved the way for the recent improvements to Sygnal and Sydent. Thanks, Shay, and welcome aboard!
And another week, another Kubernetes Helm Chart update, this time seeing matrix-synapse updated to 1.42.0 - as well as a whole lot of fixes to support the new ingress object version introduced in Kubernetes 1.19
Hi folks, we're massively pleased to announce the third major release of the TS/JS bridging library matrix-appservice-bridge. This release contains several large breaking changes to the previous way of life, most notably we have stopped using the matrix-js-sdk for most of our code, instead using the matrix-bot-sdk (Hi TravisR , we see you up there!).
There are several reasons why we went this way:
Notably, this library focuses work on simply implementing APIs and bridge/bot logic. There is no additional cruft to support client use-cases or browsers.
It's historically had a brilliant coverage of the CS and AS APIs, and has been extremely flexible to add new stable and unstable APIs to it.
At the start of this project, it was the only library with a complete Typescript coverage. Typescript types continue to be extremely useful to us.
We're hoping to make use of the upcoming encrypted appservices support, to replace the slightly janky pantalaimon support the bridge library currently uses.
Thanks to Travis and the matrix.org bridge team for working through these changes!
There are a bunch of common sense improvements that break API compatibility in this release also, so please be sure to check them out and update. We don't anticipate supporting 2.X except for extreme circumstances.
Finally, we'll be updating the matrix-org suite of bridges over the coming weeks so please watch for bugs and let us know how we're doing!
SchildiChat is a fork of Element that focuses on UI changes such as message bubbles and a unified chat list for both direct messages and groups, which is a more familiar approach to users of other popular instant messengers.
After a couple of weeks/months of internal testing and public beta testing, the latest stable version (1.2.0.sc42) now supports UnifiedPush!
This means that you can now choose your own push provider, if you do not want to use Google's FCM push notifications.
Huge thanks to @sim_g:matrix.org for working on this!
You might remember my short story from last TWIM about the race between different translators? Seems like that one was good enough to motivate a few people to contribute translations. While those don't seem to be 100% complete yet, we saw a significant jump in translation percentages (especially Portuguese), so thank you to everyone who contributed to that!
Thulinma also made the whole userprofile scrollable, which improves the experience on small screens a lot. He also implemented message deduplication by event id, which is required by the spec to be done on the client side. This fixes a lot of duplicates when using conduit and your join event appearing 2~3 times on synapse.
We also fixed an issue with how different homeservers update one time key counts and added some additional code to remove old one time keys, if we ever uploaded to many (which might have happened in the past in a few edge cases). We also now escape img tags in usernames correctly in more places, redundant date separators when paginating back in a room should not appear anymore and tastytea decreased the margins on blockquotes, so that they look less jarring and take up less space.
The biggest news is that multi-account support landed in fractal-next (don’t be fooled by the title of the MR, it’s more than just a widget!). I feel like this is one of the most requested features across all clients, yet not many have it yet, and I’m ecstatic that we’re joining them 🎉. This work was done as part of GSoC by Alejandro under the mentorship of Julian 👏.
Element Android 1.2.1 has been release to the beta channel of the PlayStore and should be push on production on next Monday. It includes improvement for the Spaces (still in beta) and improvement for the VoIP. Full changelog can be found here: https://github.com/vector-im/element-android/releases/tag/v1.2.1
v0.6.0-beta.2 has been published of matrix-bot-sdk as an early version to support encryption on bots and improvements to appservices. It's a bit self-directed to figure out how it works, but #matrix-bot-sdk:t2bot.io is available to try and help out.
Please give it a go and report bugs. The final v0.6.0 release is expected to contain not only encryption support for bots, but also appservices and real documentation. For now though, it's just the bots.
It's an "automation backend" bot of etke.cc and has following features:
send html forms from your website directly to matrix
manage matrix-registration invite tokens in matrix chat
Miounne hits first stable release. I already shared some info about it here some time ago... but now it's stable! Source code has 83+% of unit tests coverage and some bizarre bug have been fixed.
Besides, now you can use pinned version of the bot (docker registry)
PS: we have #miounne:etke.cc room to discuss (whine) and post updates about it
Patience, a full stack integration testing approach for Matrix clients and servers, has added initial support for Hydrogen this week. As it already supported Element Web, we now have a (basic) system for testing multiple clients together which is taking shape! 🥳 From here, we plan to add configuration options to express the permutations of clients you want to test together.
This project is still in its early stages, but we hope to eventually have support for many different clients and then use it to test common flows like user verification, which can differ quite a lot across clients. If you're interested in this topic, feel free to join the new #matrix-patience:matrix.org room.
This release includes changes that you may need to be aware of before upgrading, such as the removal of two deprecated Admin APIs or a retroactive fix to ensure that email notifications are only sent to addresses which are presently associated with an account. Please see the Upgrade Notes for details.
Synapse 1.42 includes support for Room Version 9, which fixes an oversight in the list of event fields which were protected from redaction in Room Version 8's restricted rooms. This makes it possible, in certain circumstances, for a restricted room to degrade into a state where participating servers will disagree about the room's membership.
Because changing a room version's redaction algorithm also changes the way that event IDs are calculated, properly fixing this issue required the creation of a new room version.
To ensure compatibility with existing servers, Synapse 1.42's MSC3244: Room version capabilities hints will continue to ask clients to prefer Room Version 8 when creating restricted rooms and Room Version 6 otherwise. A future release of Synapse will ask clients to prefer Room Version 9 for restricted rooms.
Very rarely, users find themselves in rooms created with unstable or experimental room versions. Then, when Synapse removes support for these versions, bad things happen. The server no longer understands how to interact with that room version, which means you can't interact with that room. And if you can't interact with that room, you can't leave.
In Synapse 1.42, rooms with unknown room versions are no longer returned down /sync. This prevents them from appearing in your client, though you may need to empty your client's cache and re-sync to see any effect.
In addition to Room Version 9 (MSC3375), this release includes:
An initial implementation of MSC3231: Token authenticated registration, which makes it possible for homeservers to disable user registration while still allowing new accounts to be made by people who know a pre-shared secret.
This MSC and its implementations were produced as part of a Google Summer of Code (GSoC) project by Callum Brown.
An updated implementation of MSC2946: Spaces Summary following recent changes to the proposal.
In addition to the usual array of improvements to performance, type hints, error messages, and documentation:
Custom Presence Router modules can now be built using Synapse's new, unified module interface which debuted in Synapse 1.37.
Code around federation event handling and authentication has been significantly refactored to improve reliability and maintainability, including extracting nearly 1,800 lines of code from the FederationHandler class into a separate FederationEventHandler class.
Backfilling history and fetching missing events now use the same code paths, reducing the potential for bugs.
Concurrently fetching the same large set of events (#10703) is now much more efficient, preventing the process hangs which were possible in prior, extreme cases.
These are just the highlights; please see the Upgrade Notes and Release Notes for a complete list of changes in this release.
Synapse is a Free and Open Source Software project, and we'd like to extend our thanks to everyone who contributed to this release, including aaronraimist, dklimpel, govynnus, and HugoDelval.
We forgot to mention that Doug is also the creator of Watch the Matrix! https://github.com/pixlwave/Watch-The-Matrix This allows you to use your Apple Watch as a native client (rather than through another iDevice)
These fellows all recently started to work for Element, and (claim!) to enjoy it. Element are HIRING, so if YOU think think you'd like to apply, check out https://apply.workable.com/elementio/ for current listings and details of how to apply.
Here's your weekly spec update! The heart of Matrix is the specification - and this is modified by Matrix Spec Change (MSC) proposals. Learn more about how the process works at https://spec.matrix.org/unstable/proposals.
You may be wondering: what's up with all of these abandoned MSCs?? The answer is that the matrix-org/matrix-doc repo changed its base branch to main to help preserve the git history since the spec website rewrite. In doing so, all PRs were automatically updated to the new base branch by github... except those that were coming from deleted users and repos. Those ones were simply closed!
But as they seemed to be have been effectively abandoned by their authors, it was more of a cleanup than an accident. However, if your MSC was affected by this change and you would like to continue it, please contact someone in the #matrix-spec-office:matrix.org and we'll help you out.
MSC2448 defines a way for clients to include a "blurhash", or a short, textual representation of a blurred version of an image, inside events which other clients can show while waiting for thumbnails to download from media servers. This replaces the potentially blank space while an image's thumbnail is loading with a (IMO) beautiful alternative!
Yes I wrote this MSC... but I swear it's what the script picked! We do not question the script!!
Synapse 1.41.1 is out and it contains patches for two security vulnerabilities which could inappropriately disclose private room metadata to unauthorized users on a participating homeserver. Please upgrade.
Room Version 9 is coming in Synapse 1.42 next week. This version fixes an oversight in which event fields are protected from redaction in room version 8, making it possible for restricted rooms to break if a join event is redacted. Because event IDs are based on the redaction algorithm, we can't fix this without creating a new room version.
In the interest of compatibility across the federation, Synapse 1.42 will still instruct clients to create restricted rooms using room version 8. Synapse 1.43, scheduled for release on 21 September, will begin instructing clients to use room version 9 instead.
Hey folks! I had some spare time today so I've invested it into the matrix-github bridge. The latest work is GitHub discussions support. It's still needs a bit more testing / minor feature implementation, but I leave you with a screenshot below of how it currently integrates spaces!
We had a race between 3 Translators this week. All 3 of them were trying really hard, so in my opinion every placement is a first place, buuuuuut Thulinma actually came first by bringing the Dutch translation from 5% to 100%. A few hours later Priit came in as a close second updating the Estonian translation to 100%. ISSOtm noticed that and tried to catch up which resulted in a 3rd place finish for the French translation. Now I understand the excitement people feel watching others compete in sports without having to do anything themselves!
red_sky (nheko.im) meanwhile fought a much more difficult enemy, Apple documentation and code signing! To be honest, I expected him to be beaten, but Nheko's DMGs are now actually properly signed and notarized. So if you are on macOS, you should now see less ugly warnings when installing Nheko. All nightlies building of the master branch are signed as well as our future releases.
In more community contributions, resolritter fixed the right click menu not working on replies. So you can copy a link from a reply now by right-clicking it without having to scroll up. Thulinma fixed window alerts not working when using conduit, because Conduit does not implement the /notifications endpoint Nheko uses and he helped me debug and fix device lists not showing up when using Conduit as well as sessions always getting rotated in "Send encrypted messages to verified devices only" mode.
In our work to stabilize E2EE we also now require a proper secrets daemon running on Linux (and other platforms, but there it is always provided by the OS). This is used to store the pickle key as well as the cross-signing secrets, so that an attacker can't read the from the config file. We already used such a daemon before, but we failed silently and we didn't use it for the pickle key until now. So if this prevents you from running Nheko, please open an issue so that we can work on a solution. Those APIs can be really fickle so additional testing and feedback would help us out a lot!
Also exciting is that Nheko now supports playing encrypted audio and video files without storing a temporary unencrypted copy on disk as well as animated images like WebP and GIF! It took us a while to figure out a proper solution, but now you can send animated stickers and you will finally be able to understand why other people were lauging at still images. (We also had to fix some bugs in our sticker editor, where we didn't add the mimetype to the sticker info for that.)
Some more embarrassing news, I didn't know I was a moderator in #conduit:fachschaften.org, so I happily pinged everyone in the room while discussing room mentions. To prevent that from happening in the future, Nheko now shows a red warning above the message input if you will be pinging the whole room to give you time to reconsider. If that is not enough to stop me from doing that, we might require confirmation before sending such messages in the future, but so far this seems to work. Pinging everyone by accident can really scare you and composing a message in Matrix shouldn't be scary!
I hope I didn't forget anything and please make sure you check out Conduit, since they are doing a great job in revealing bugs in Nheko!
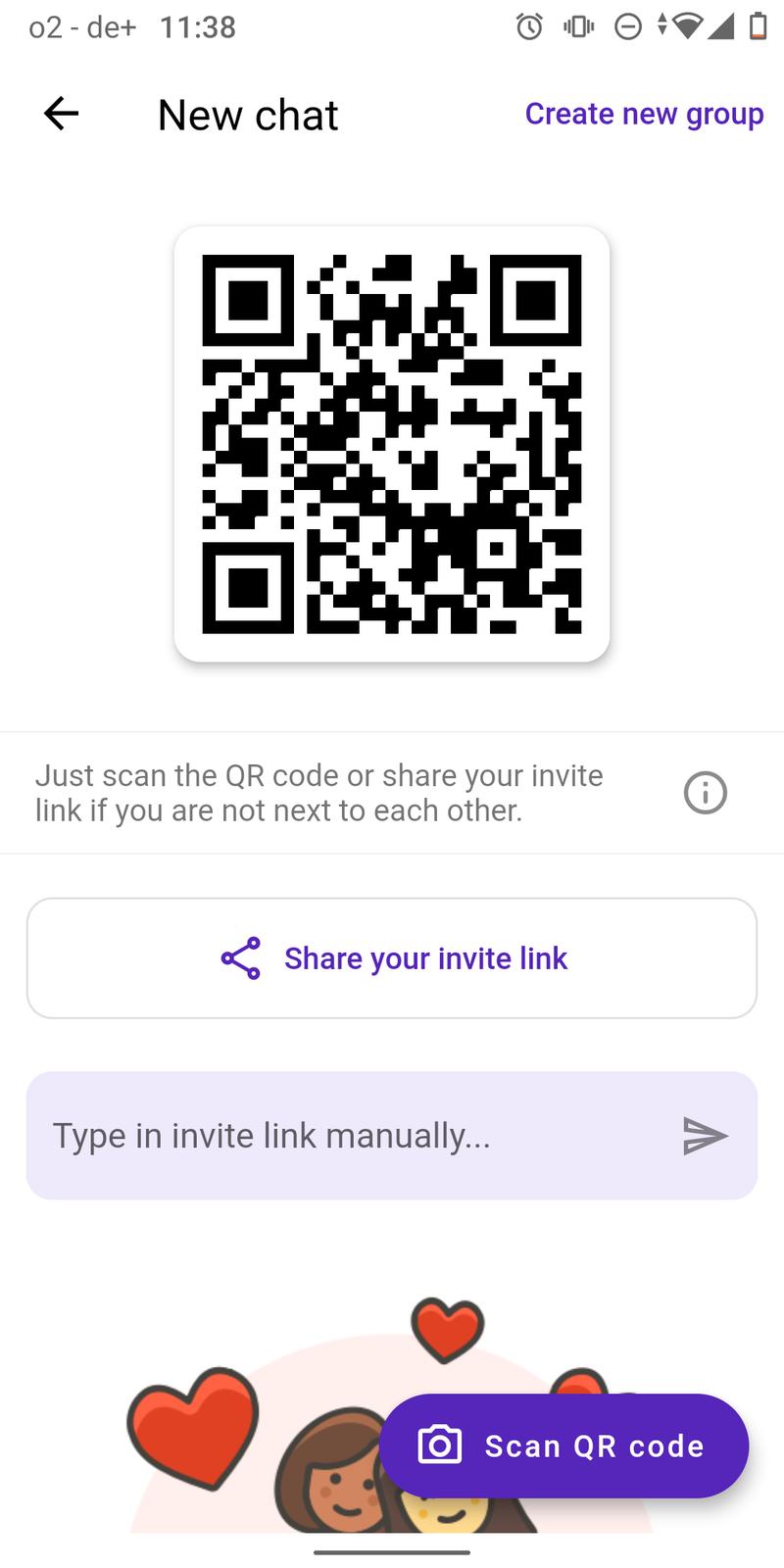
This release fixes a bug which makes it impossible to send images in unencrypted rooms. It also implements a complete new designed new chat page which now uses a QR code based workflow to start a new chat.
feat: Dismiss keyboard on scroll in iOS
feat: Implement QR code scanner
feat: New design for new chat page
feat: Use the stripped body for notifications and room previews
feat: Send on enter configuration for mobile devices
fix: Prefix of notification text
fix: Display space as room if it contains unread events in timeline
We’ve added an early, incomplete prototype of Threads to Labs
Bug fixes
iOS
App startup has been improved by x3 by lazy loading room messages and read receipts
Element-iOS is now iOS12 minimum. Code have been cleaned up
URL preview is still in progress but it should be available in the next release, 1.5.3
SwiftUI: There is now a target to run the Xcode project without the MatrixSDK to speedup SwiftUI preview. This is the first piece for the coming new screen templates
Android
Working on upgrading Android Gradle Plugin to 7.0.2 and other dependencies.
Set up GitHub actions and reduce the number of tasks run by Buildkite
Spaces PRs are merged one by one to develop, the feature will be available in the coming releases
Working on crypto: dehydrated devices, Olm fallback keys
This version of the simplematrixbotlib package adds the ability to send messages formatted in markdown via the bot.api.send_markdown_message() method. Example usage is shown below:
#### Respond to all messages from users with a hello world message that involves markdown formatting
import simplematrixbotlib as botlib
creds = botlib.Creds("https://home.server", "user", "pass")
bot = botlib.Bot(creds)
@bot.on_message_event
async def hello_world_md(room, message):
match = botlib.MessageMatch(room, message, bot)
markdown_message = "# Hello World from [simplematrixbotlib](https://github.com/KrazyKirby99999/simple-matrix-bot-lib)!"
if match.is_not_from_this_bot():
await bot.api.send_markdown_message(
room_id=room.room_id,
message=markdown_message)
bot.run()
We're getting very close to a real App Store launch. The latest beta release this week is 0.98 This version might be The One! So please, if you haven't tried Circles in a while, give this one a shot. Also please share the link with any friends and family who you think might be interested. The current signup token has plenty of slots for everyone.
If you want to see some activity in your circles, invite me to follow your Community circle and I'll invite you to follow back. I'm @cvwright:kombucha.social.
If you've been using Circles with your own (non-Kombucha) server, you probably DO NOT WANT this version. Support for bring-your-own-server will return very soon after our App Store launch.
Broke and then re-enabled new account signup. Thanks to everyone who helped diagnose this one, and sorry if you were unable to sign up using a recent build.
Fixed a weeks-old bug where posting a message into a circle would then send you back to your list of all your social circles. Big thanks to Yosef for bringing this to my attention.
Fixed a bug in recent 0.9x builds where the Matrix rooms underlying circles and groups were being created with invalid encryption parameters. If you've been unable to post anything, this is the likely culprit. The fix is to update to the latest build, then delete your old circles/groups and create new ones.
We have a new icon. It's blue! I was worried that Apple might think the old icon looked too much like the Apple Photos icon.
New and improved interface for managing your account information. Added support for changing your password and for deactivating your account. I hope you never want this last one, but Apple requires it for apps that allow you to create accounts.
Removed support for Markdown formatting in posts and image captions. This is a sad one, but unfortunately the performance of the open source library that we were using for Markdown just wasn't up to the task. On the bright side, our timelines load much more quickly now, and the scrolling should be much smoother. Look for Markdown support to return with the release of iOS 15 later this year.
Another update to the Recent Activity list. Now it should refresh itself automatically if/when it initially comes up empty.
The CoMatrix project enables the usage of the Matrix protocol (more precisely Matrix Client-Server API) for constrained IoT devices via CoAP and CBOR in a constrained network (e.g. a 802.15.4/6LoWPAN network).
CoMatrix provides a gateway, which ports Matrix to CoAP/CBOR/(DTLS). This gateway communicates with constrained IoT devices on one side via CoAP+CBOR and translates to the Matrix protocol on the other side (i.e. HTTP+JSON). CoMatrix also provides a client library (for RIOT-OS) which is a starting point to implement CoMatrix clients (for constrained devices) which are able to interact with Matrix homeservers via the gateway.
Currently CoMatrix supports the following features:
I have made a small 120k pipeline-agent software (including all dependencies except NodeJS v8) which can run on multiple platforms (including OpenWRT) and takes pipeline work over the Matrix protocol. In the end it's going to be used to setup things like VPN connections between gateways.
We also have a commercial web portal almost published where one can create web apps and configure pipelines to process the results. And yes, the portal also uses Matrix as its persistent storage -- it was implemented using my Matrix CRUD Repository from last week :)
The agent software (pipeline-runner) is open source and has zero (0) runtime dependencies except NodeJS, and available from here: https://github.com/sendanor/pipeline-runner -- It's still in early development, though.
Hi everyone! Did you ever feel lost in the Matrix world? The room directory is big, but it's still hard to find something you like. Or are you a room moderator, but there is not much activity in your room because it doesn't have enough users?
This is why I want to share rooms (or spaces) I find interesting.
"Discover music through peers - Please write a small description of your discoveries. No uploads of non-free music please. For discussions and chat please visit the room's sibling #musicdiscussion:matrix.org "

.png)