Matrix & Riot for Cryptocurrency Communities
2017-09-19 — Thoughts — Matthew HodgsonHi folks,
Over the last few weeks there's been a huge movement in the cryptocurrency communities over needing to find a better communication medium than Slack. Some of the biggest communities for projects like Status, Aragon, TenX, Tezos, OmiseGo, Polkadot and many others are getting overrun by phishing attacks where malicious users have set up bots which auto-DM users joining the room in order to try to extract private keys to steal funds. Slack has very limited support for avoiding this sort of abuse (especially at the free service tiers), so the search is on for an alternative solution. There seems to be some confusion over what Matrix & Riot can and can't do to help the situation, so we thought we'd write a blog post about it (especially after we had so much fun at the ETHLDN meetup last week!).
To be clear: we see Ethereum, Bitcoin, Ripple, Stellar and all the other decentralised currencies as being very closely related to Matrix. Just as distributed ledgers disrupt the fragmented oligopoly old-school banking industry, we want Matrix to disrupt the relatively old-school communications systems of today. And so we'd really rather like that Matrix and Riot rocked when it comes to supporting cryptocurrency communities, and this is something we intend to dedicate resources to long term: we've got some big plans.
🔗Things Matrix provides:
Decentralisation. Rather than each community having its own silo, with users having to juggle accounts over all of them, Matrix decentralises rooms over all the different servers. Users can have a single account and still jump into all the other communities (as well as the rest of the Matrix universe). However, each community can run its own server instance (if they want to) and have complete control over its behaviour.
Encryption. Matrix has first-class end-to-end encryption (although the UX in Riot needs refinement and is technically still beta). This is great for encrypting rooms which need privacy - although it does come at the expense of being able to do server-side content filtering, which is desirable for fixing phishing attacks. So you probably don't want to turn on encryption for rooms which need phish filtering (or you could use a bot to decrypt and autoremove malicious content).
A standard real-time API. One bit of feedback we've heard recently is that “Riot has no realtime API”. This is spectacularly untrue; Riot is a client for the Matrix protocol, which is in and of itself an open standard realtime API for messaging, which you can use for writing whatever bots and extensions your heart desires.
Finely grained permissions per room. Likewise there seems to be some confusion over Matrix's access control model. In Matrix, each user in a room has a ‘power level' - typically a number between 0 and 100. By convention, normal users who have just joined the room have 0; the room creator and ‘admins' have 100; and ‘moderators' have 50. Pretty much every access you can do in a room then has a threshold which defines how much power a user needs to perform the action. It doesn't get much more finely grained than this!
Ability to disable DMs and room invites. Architecturally Matrix lets you prevent users who use a given server from receiving invites (the homeserver can just autoreject the invites, based on some set of rules). We're currently putting together a quick demo to show this off in the Synapse server implementation, but it boils down to having an option to cancel invites here (federated) and here (local).
Check out the demo below!
Ability to filter content. Similarly, Matrix architecturally lets a given server filter out messages based on content or some other pattern from being received by its users. We're also putting together a demo of this too in Synapse, which boils down to redacting inappropriate events here (federated) and here (local). The demo isn't quite ready yet but we'll update this & yell when it is.
Check out the demo below!
UPDATE
the DM/invite disabling and spam/phish filtering code has now landed on the develop branch of Synapse, and we've deployed an demo example of it at https://phishfree.riot.im. Messages containing the word 'SPAM' are filtered, and invites are disabled (unless you are the local server admin).
Other stuff. Matrix and Riot give loads of other fun stuff too:
- Widgets - the ability to embed arbitrary apps into your rooms (video conferences; currency tickers; DApps; wallets; monitoring dashboards; etc.).
- 100% Native clients on iOS & Android (including Jitsi video conferencing & Widgets, as of the develop branch!)
- Read receipts! (how can you live without them on Slack?!)
- Internationalised to 20+ languages (thanks to the community! :)
- Bridges through to IRC, Slack, Gitter, and more.
- All sorts of alternative clients (e.g. nheko, quaternion) and SDKs
- Insanely scalable and performant next-generation server ( Dendrite) on the horizon
- An open spec for the protocol.
- 100% Apache-licensed FLOSS. Riot/Web is particularly easy to hack on and theme & customise as needed.
- Ability to disable federation for a room if you really want to lock it down to the users & rules of a single server.
🔗Things we need to improve:
**Groups (aka Communities): **One of the biggest missing features in Matrix is the ability to define groups of users & rooms, similar to a Slack team or Discord server, which can be used to organise together a set of discussions and generally give a feeling of community. We've been working hard at this and expect to see it land in Riot/Web in the next few weeks. In the meanwhile, you can see some of the UX we're aiming for here!
**E2E UX (and Riot UX in general): **While the underlying encryption of Matrix is solid, the UX exposed by Riot needs considerable work - specifically to improve the device verification flow and automatically share keys between trusted devices. We're continuing to work on this over the next few months. Likewise there are many areas for possible improvement in Riot's overall UX and design that we're working through as urgently as we can.
Active Application Services: The per-server filtering described above is good if you just want to protect users on a given server (e.g. the server you point your community at). However, if you want to filter all the messages for a given room which may be federated over multiple servers, you need a way to define a centralised chokepoint to define the filtering rules. Architecturally this is meant to be performed by an ‘Active Application Service' in Matrix, but we've not yet defined or implemented this API. The idea for the room to define a list of services that messages are filtered through by all servers before they may be accepted for the room. This would be the ideal solution to the phishing-filtering problem, but in practice filtering just local users (and perhaps disabling federation for particularly sensitive rooms or servers) is probably good enough for the immediate problem here.
Hope this provides some much-needed clarity to the debate! If there are other features cryptocurrency communities need to thrive please let us know, as we'd like to actively help to support decentralized communities. #matrix-dev:matrix.org is probably the best place for further questions :)
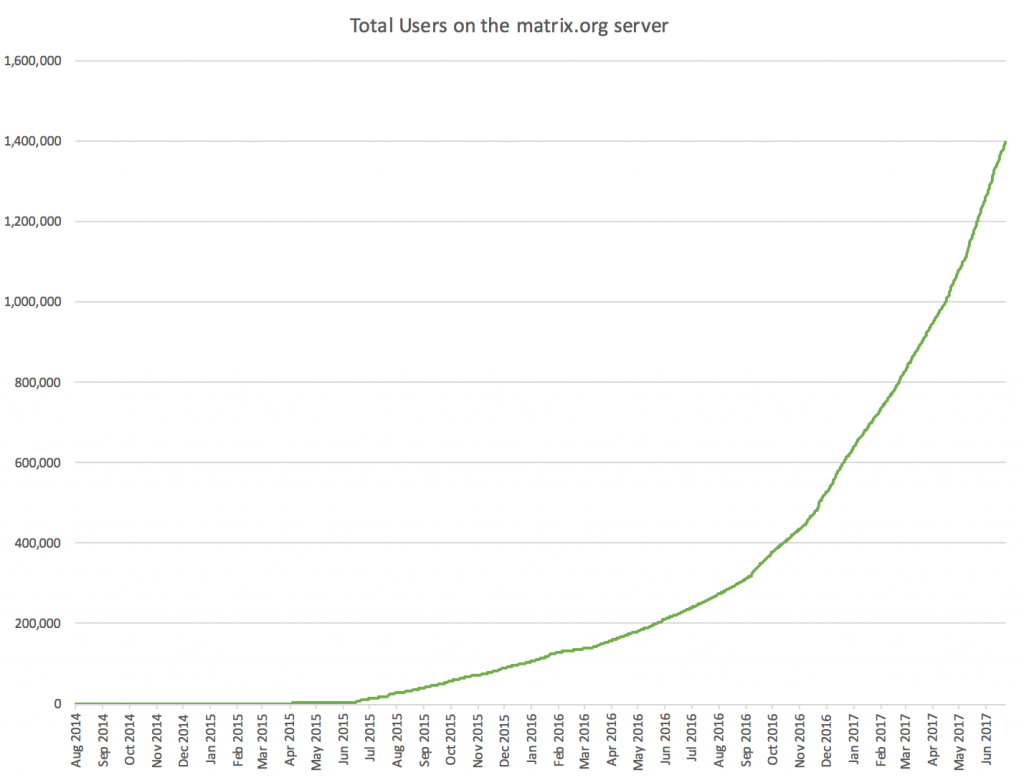
Finally: one thing that has come up a few times in this discussion has been “Matrix's funding crisis means they may not be here to stay”. All I can say is that Matrix is here to stay. Even if the core team ended up just being Matthew hacking away by himself funded by Patreon/ Liberapay, we have a large and passionate wider dev community who aren't going anywhere. But more importantly (and not wishing to jinx it), in the last few weeks we have received offers of significant funding which may hopefully resolve the funding crisis for the foreseeable. Nothing is signed yet, but watch this space, and meanwhile I strongly suggest betting on Matrix being here to stay!
--Matthew