Hi all,
Just over a week ago we had the honour of using Matrix to host FOSDEM: the world's largest free & open source software conference. It's taken us a little while to write up the experience given we had to recover and catch up on business as usual... but better late than never, here's an overview of what it takes to run a ~30K attendee conference on Matrix!
 [confetti and firework easter-eggs explode over the closing keynote of FOSDEM 2021]
[confetti and firework easter-eggs explode over the closing keynote of FOSDEM 2021]
First of all, a quick (re)introduction to Matrix for any newcomers: Matrix is an open source project which defines an open standard protocol for decentralised communication. The global Matrix network makes up at least 28M Matrix IDs spread over around 60K servers. For FOSDEM, we set up a fosdem.org server to host newcomers, provided by Element Matrix Services (EMS) - Element being the startup formed by the Matrix core team to help fund Matrix development.
The most unique thing about Matrix is that conversations get replicated across all servers whose users are present in the conversation, so there's never a single point of control or failure for a conversation (much as git repositories get replicated between all contributors). And so hosting FOSDEM in Matrix meant that everyone already on Matrix (including users bridged to Matrix from IRC, XMPP, Slack, Discord etc) could attend directly - in addition to users signing up for the first time on the FOSDEM server. Therefore the chat around FOSDEM 2021 now exists for posterity on all the Matrix servers whose users who participated; and we hope that the fosdem.org server will hang around for the benefit of all the newcomers for the foreseeable so they don't lose their accounts!
Talking of which: the vital stats of the weekend were as follows:
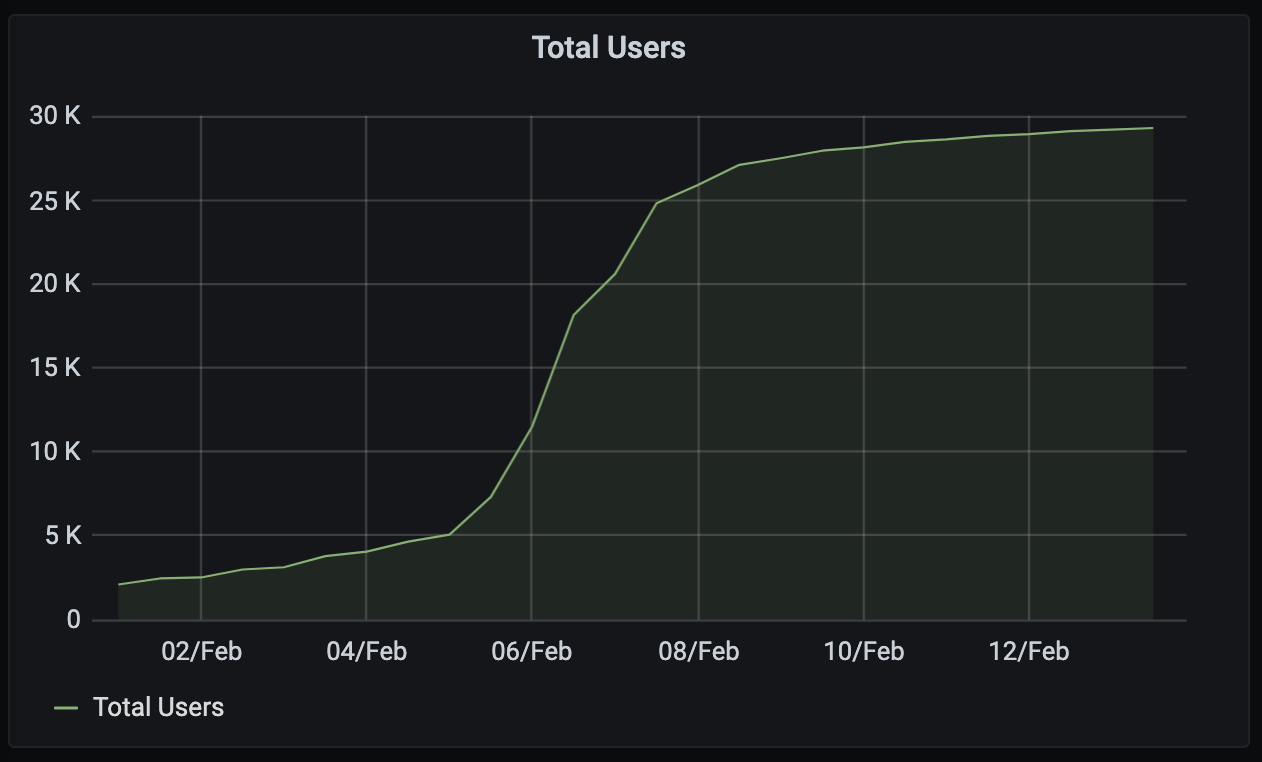
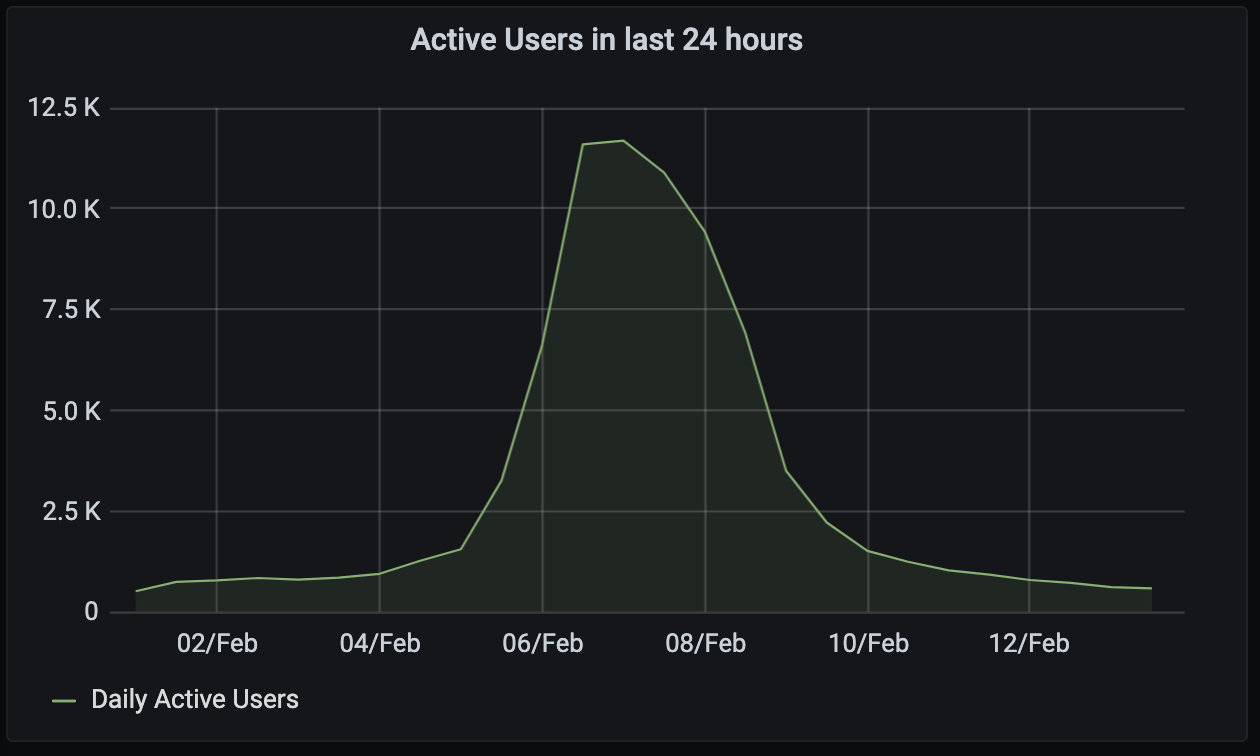
- We saw almost 30K local users on the FOSDEM server + 4K remote users from elsewhere in Matrix.
- There were 24,826 guests (read-only invisible users) on the FOSDEM server.
- There were 8,060 distinct users actively joined to the public FOSDEM rooms...
- ...of which 3,827 registered on the FOSDEM server. (This is a bit of an eye-opener: over 50% of the actively participating attendees for FOSDEM were already on Matrix!)
- These numbers don't count users who were viewing the livestreams directly, but only those who were attending via Matrix.
Given last year's FOSDEM had roughly 8,500 in-person attendees at the Université libre de Bruxelles, this feels like a pretty good outcome :)
Graphwise, local user activity on the FOSDEM server looked like this:
🔗How was it built?
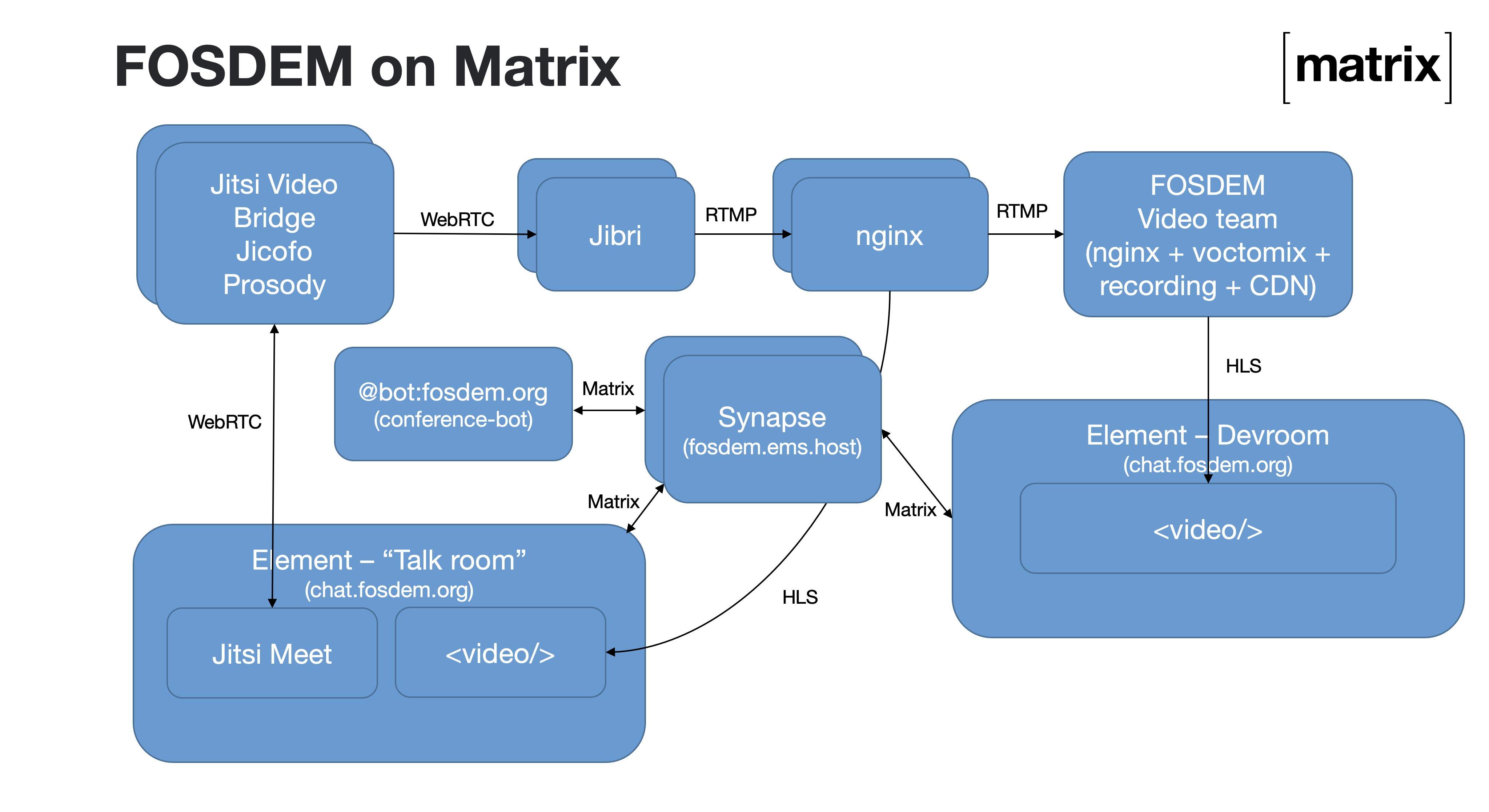
There were four main components on the Matrix side:
- A horizontally-scalable Matrix server deployment (Synapse hosted in EMS)
- A Jitsi cluster for the video conferencing, used to host all the Q&A sessions, hallway sessions, stands, and other adhoc video conferences
- An elastically scalable Jibri cluster used to livestream the Jitsi conferences both to the official FOSDEM livestreams and to provide a local preview of the conference on Matrix (to avoid the Jitsis getting overloaded with folks who just want to view)
- conference-bot - a Matrix bot which orchestrated the overall conference on Matrix, written from scratch for FOSDEM by TravisR, consuming the schedule from FOSDEM and maintaining all the necessary rooms with the correct permissions, widgets, invites, etc.
Architecturally, it looked like this:
On the clientside, we made heavy use of widgets: the ability to embed arbitrary web content as iframes into Matrix chatrooms. (Widgets currently exist as a set of proposals for the Matrix spec, which have been preemptively implemented in Element.)
For instance, the conference-bot created Matrix rooms for all the FOSDEM devrooms with a predefined widget for viewing the official FOSDEM livestream for that room, pointing at the appropriate HLS stream at stream.fosdem.org - which looked like this:
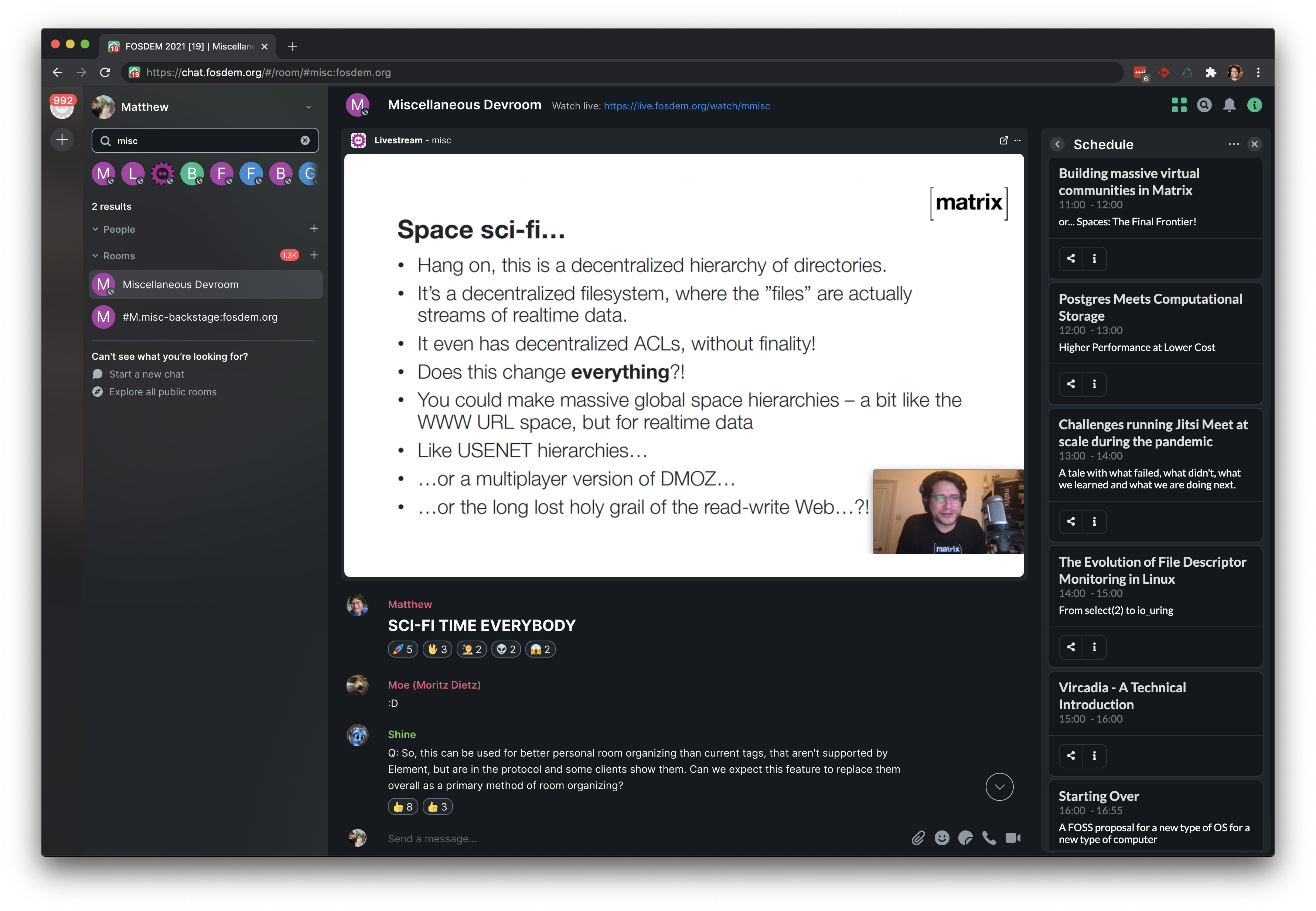
Each devroom also had a schedule widget available on the righthand side, visualising the schedule of that room - huge thanks to Hato and Steffen and folks at Nordeck for putting this together at the last minute; it enormously helped navigate the devrooms (and even had a live countdown to help you track where you were at in the schedule!)
Each devroom was also available via IRC on Freenode via a dedicated bridge (#fosdem-...) and via XMPP.
The bot also created rooms for each and every talk at FOSDEM (all 666 of them), as the space where the speaker and host could hang out in advance; watch the talk together, and then broadcast the Q&A session. At the end of the talk slot, the bot then transformed the talk room into a 'hallway' for the talk, and advertised it to the audience in the devroom, so folks could pose follow-on questions to the speaker as so often happens in real life at FOSDEM. The speaker's view of the talk rooms looked like this:
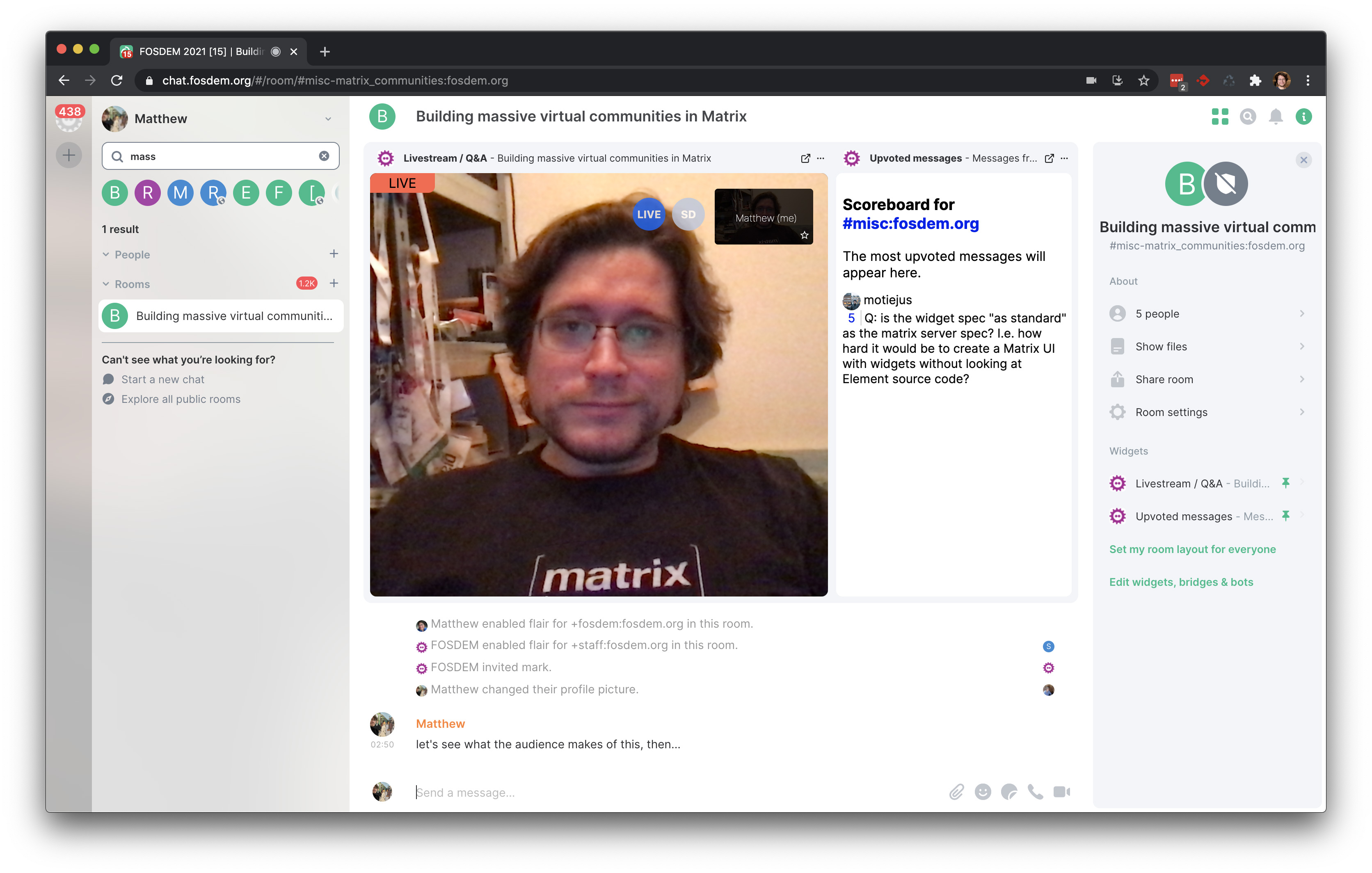
On the right-hand side you can see a "scoreboard" - a simple widget which tracked which messages in the devroom had been most upvoted, to help select questions for the Q&A session. On the left-hand side you can see a hybrid Jitsi/livestream widget used to coordinate between the speaker & host. By default, the widget showed the local livestream of the video call - if you clicked 'join conference' you'd join the Jitsi itself. This stopped view-only users from overloading the Jitsi once the room became public.
The widgets themselves were hosted by the bot (you can see them at https://github.com/matrix-org/conference-bot/tree/main/web). Meanwhile the chat.fosdem.org webclient itself ended up being identical to mainline Element Web 1.7.19, other than FOSDEM branding and being configured to hook the 'video call' button up to the hybrid Jitsi/livestream widget rather than a plain Jitsi.
Meanwhile, for conferencing we hosted an off-the-shelf Jitsi cluster sized to ~100 concurrent conferences, and for the Jibri livestreaming we set up an elastic scalable cluster using AWS Auto Scaling Groups. Jibri is essentially a Chromium which views the Jitsi webapp, running in a headless X server whose framebuffer and ALSA audio is hooked up to an ffmpeg process which livestreams to the appropriate destination - so we chose to run a separate VM for every concurrent livestream to keep them isolated from each other. The Jibri ffmpegs compressed the livestream to RTMP and relayed it to our nginx, which in turn relayed it to FOSDEM's livestreaming infrastructure for use in the official stream, as well as relaying it back to the local video preview in the Matrix livestream/video widget.
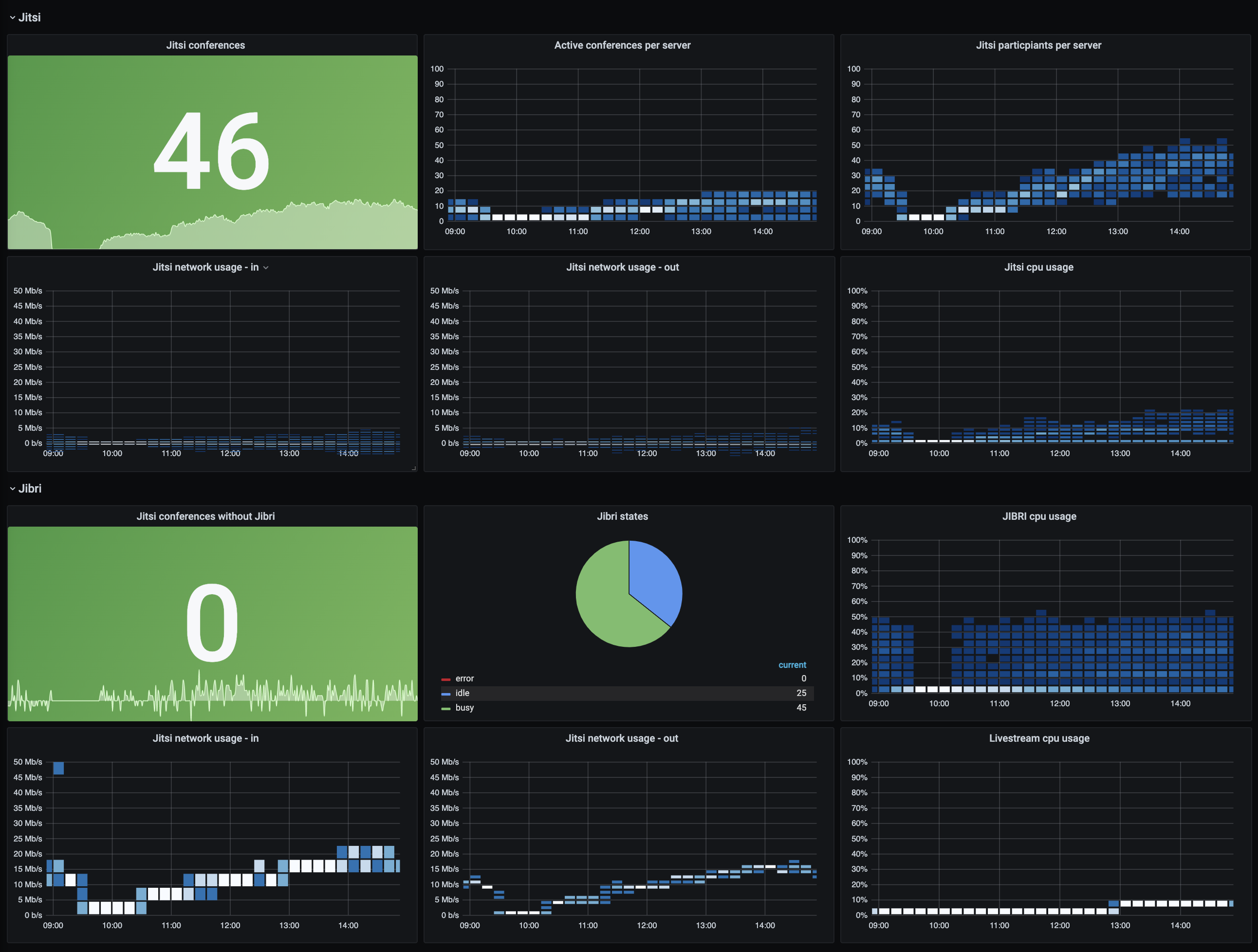
Here's a screengrab of the Jitsi/Jibri Grafana dashboard during the first day of the conference, showing 46 concurrent conferences in action, with 25 spare jibris in the scaling group cluster ready for action if needed :)
There was also an explosion of changes to Element itself to try to make things go as smoothly as possible. Probably the most important one was implementing Social Login - giving single-click registration for attendees who were happy to piggyback on existing identity providers (GitHub, GitLab, Google, Apple and Facebook) rather then signing up natively in Matrix:
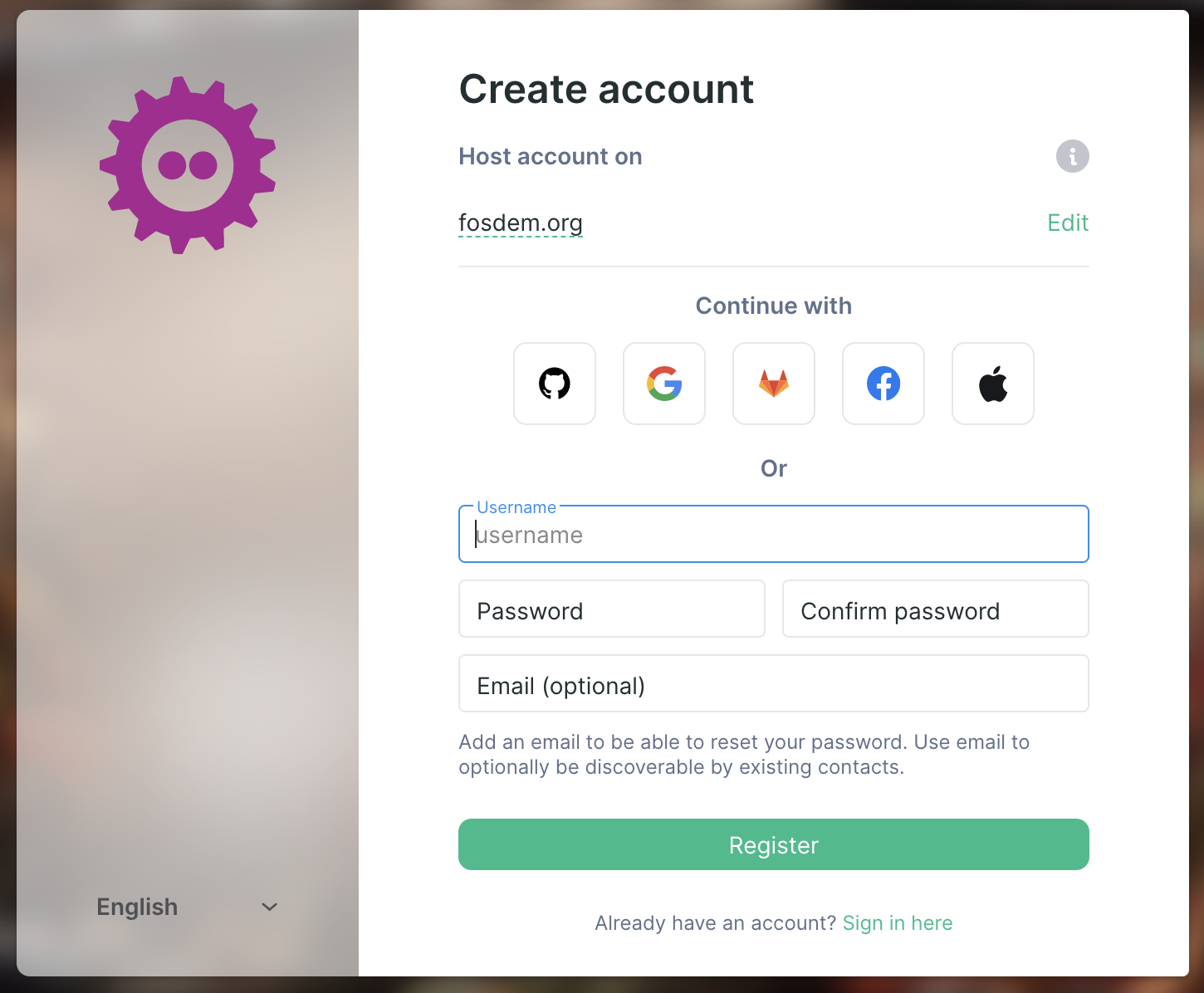
This was a real epic to get together (and is also an important part of achieving parity between Gitter and Element) - and seems to have been surprisingly successful for FOSDEM. Almost 50% of users who signed up on the FOSDEM server did so via social login! We should also be turning it on for the matrix.org server this week.
Finally, on the Matrix server side, we ran a cluster of synapse worker processes (1 federation inbound, reader and sender, 1 pusher, 1 initial sync worker, 10 synchrotrons, 1 event persister, 1 event creator, 4 general purpose client readers, 1 typing worker and 1 user directory) within Kubernetes on EMS. These were hooked up for horizontal scalability as follows:
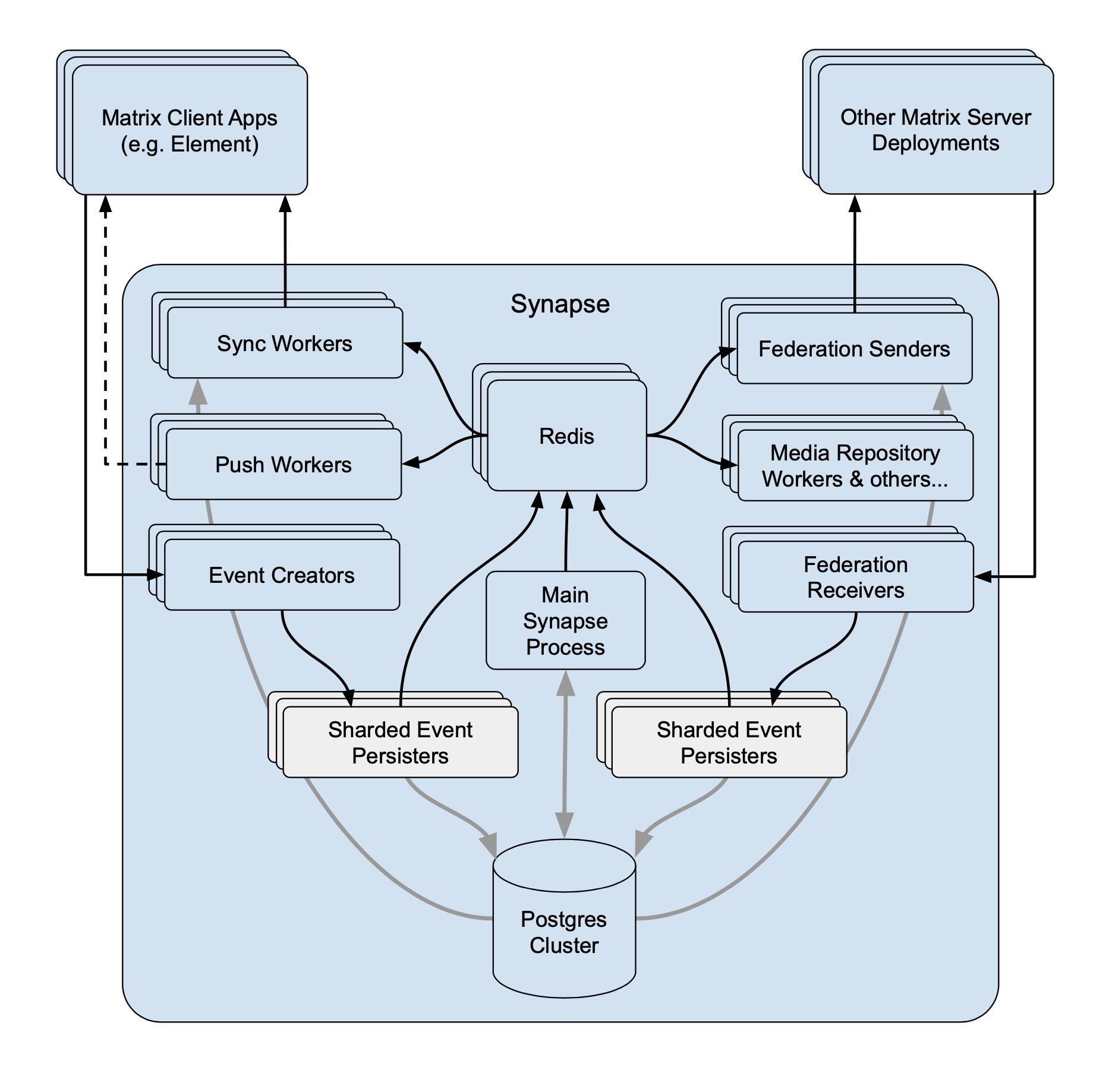
The sort of traffic we saw (from day 2) looked like this:
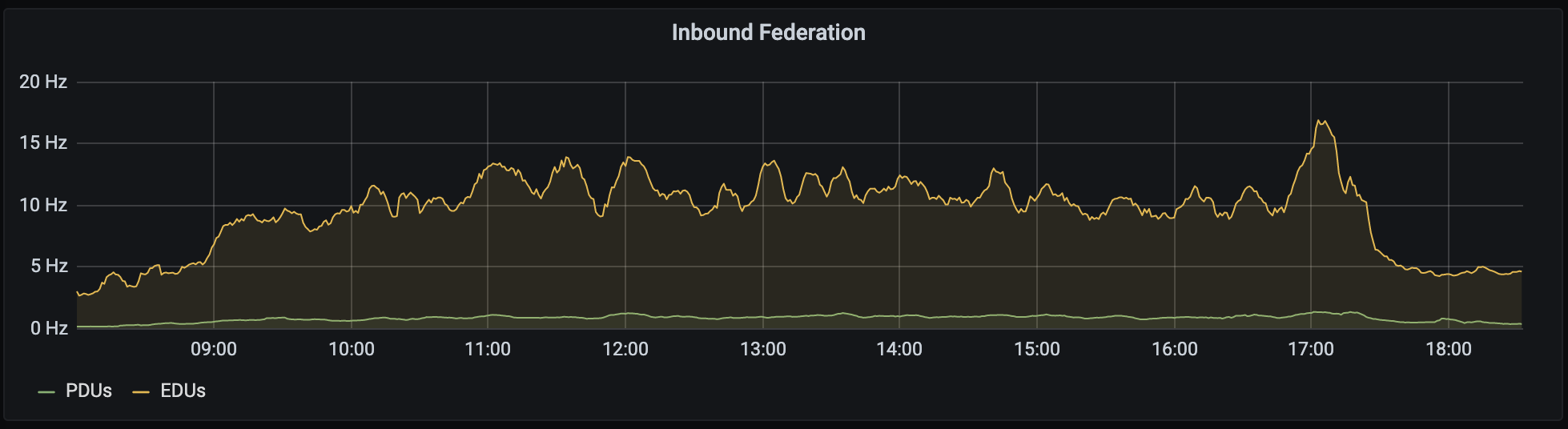
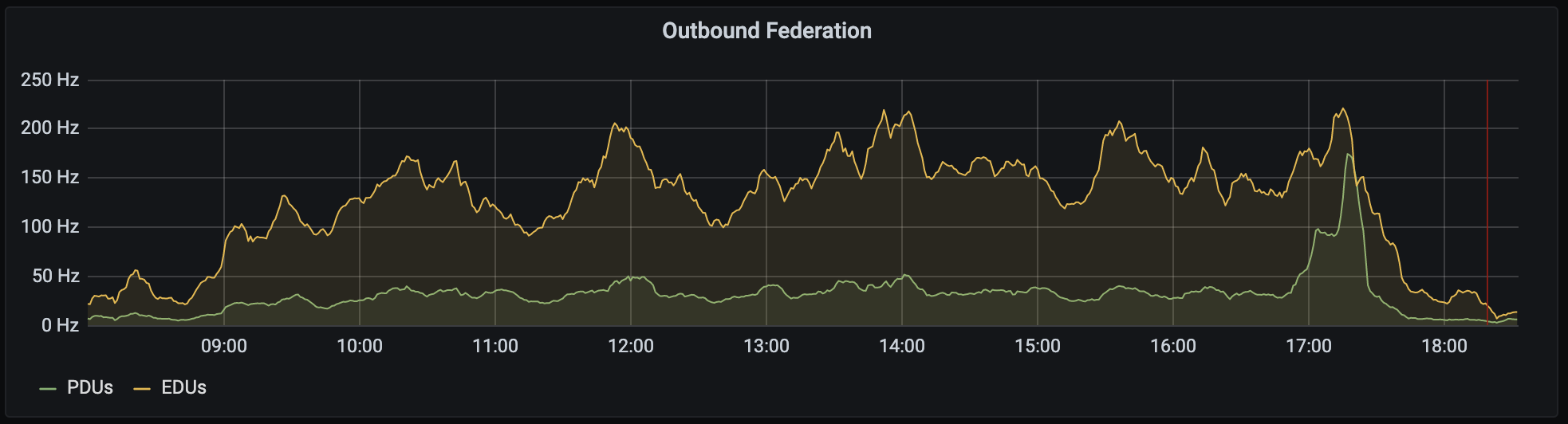
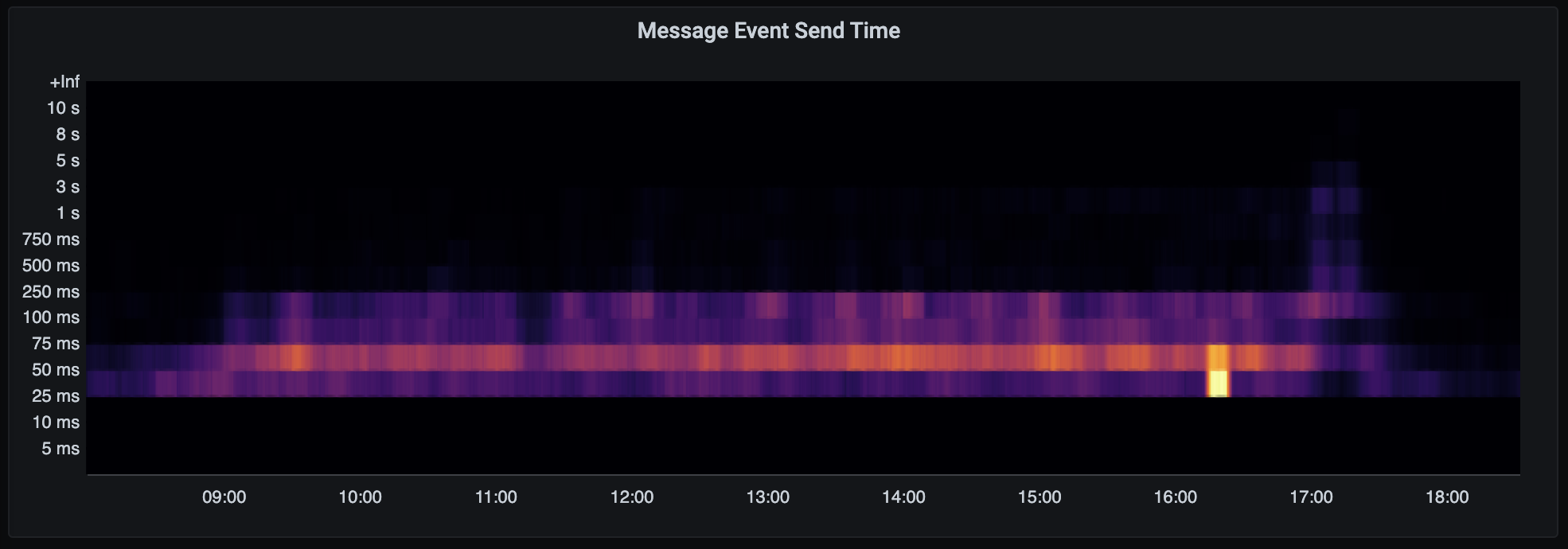
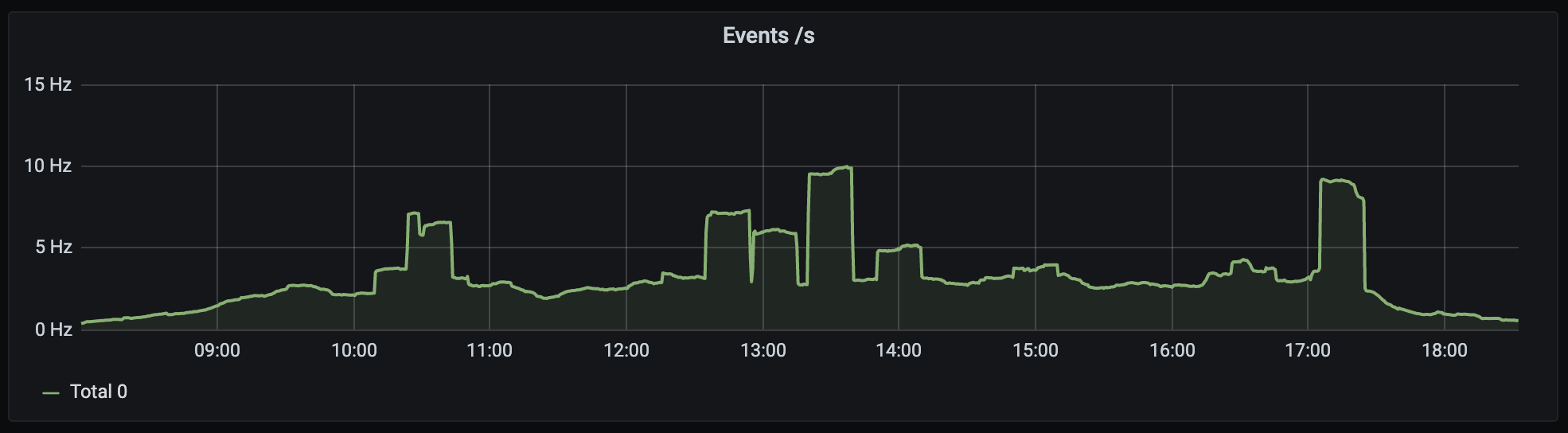
🔗How did it go?
Overall, people seem to have had a good time. Some folks have even been kind enough to call it the best online event they've been to :) This probably reflects the fact that FOSDEM rocks no matter what - and that Matrix is an inherently social medium, built by and for open source communities (after all, the whole Matrix ecosystem is developed over Matrix!). Also, Matrix being an open network means that folks could join from all over, so the social dynamics already present in Matrix spilled over into FOSDEM - and we even saw a bunch of people spin up their own servers to participate; literally sharing the hosting responsibility themselves. Finally, having critical infrastructure rooms available such as #beerevent:fosdem.org, #cafe:fosdem.org and #food-trucks:fosdem.org probably helped as well.
That said, we did have some production incidents which impacted the event. The most serious one was on Saturday morning, where it transpired that some of the endpoints hosted on the main Synapse process were taking way more CPU than we'd anticipated - most importantly the /groups endpoints which handle traffic relating to communities (the legacy way of defining groups of rooms in Matrix). One of the last things we'd done to prepare for the conference on Friday night was to create a +fosdem:fosdem.org community which spanned all 1000 public rooms in the conference, as well as add the +staff:fosdem.org community to all of those rooms - and unfortunately we didn't anticipate how popular these would be. As a result we had to do some emergency rebalancing of endpoints, spinning up new workers and reconfiguring the loadbalancer to relieve load off the main process.
Ironically the Matrix server was largely working okay during this timeframe, given event-sending no longer passes through the main process - but the most serious impact was that the conference bot was unable to boot due to hitting a wide range of endpoints on startup as it syncs with the conference, some of which were timing out. This in turn impacted widgets, which had been hosted by the bot for convenience, meaning that the Jitsi conferences for stands and talk Q&A were unavailable (even though the Jitsi/Jibri cluster was fine). This was solved by lunchtime on Saturday: we are really sorry for folks whose Q&As or conferences got caught in this. On the plus side, we spotted that many affected rooms just added their own widgets for their own Jitsis or BBBs to continue with minimal distraction - effectively manually taking over from the bot.
The other main incident was briefly first thing on Sunday morning, where two Jibri livestreams ended up trying to broadcast video to the same RTMP URL (potentially due to a race when rapidly removing and re-adding the jitsi/livestream widget for one of the stands). This caused a cascading failure which briefly impacted all RTMP streams, but was solved within about 30 minutes. We also had a more minor problem with the active speaker recognition malfunctioning in Jitsi on Sunday (apparently a risk when using SCTP rather than Websockets as a transport within Jitsi) - this was solved around lunchtime. Again, we're really sorry if you were impacted by this. We've learned a lot from the experience, and if we end up doing this again we will make sure these failure modes don't repeat!
Other things we'd change if we have the chance to do it again include:
- Providing a to-the-second countdown via a widget in the talk room so the speaker & host can see precisely when they're going 'live' in the devroom (and when precisely they're going to be cut in favour of the next talk)
- Providing a scratch-pad of some kind in the talk room so the host & speaker can track which questions they want to answer, and which they've already answered
- Keep the questions scoreboard and scratchpad visible to the speaker/host after their Q&A has finished so they can keep answering the questions in the per-talk room, and advertise the per-talk room more effectively.
- Use Spaces rather than Communities to group the rooms together and automatically provide a structured room directory! (Like this!)
- Use threads (once they land!) to help structure conversations in the devroom (perhaps these could even replace the hallway rooms?)
- Make the schedule widgets easier to find, and have more of them around the place
- Make room directory easier to find.
- Give the option of recording the video in the per-talk and stands for posterity
- Provide more tools to stands to help organise demos etc.
So, there you have it. We hope that this shows that it's possible to host successful large-scale conferences on Matrix using an entirely open source stack, and we hope that other events will be inspired to go online via Matrix! We should give a big shout out to HOPE, who independently trailblazed running conferences on Matrix last year and inspired us to make FOSDEM work.
If you want to know more, we also did a talk about FOSDEM-on-Matrix in this month's Open Tech Will Save Us meetup and the Building Massive Virtual Communities on Matrix talk at FOSDEM went into more detail too. Our historical Taking FOSDEM online via Matrix blog has been somewhat overtaken by events but gives further context still.
Finally, huge thanks to FOSDEM for letting Matrix host the social side of the conference. This was a big bet, starting from scratch with our offer to help back in September, and we hope it paid off. Also, thanks to all the folks at Element who bust a gut to pull it together - and to the FOSDEM organisers, who were a real pleasure to work with.
Let's hope that FOSDEM 2022 will be back in person at ULB - but whatever happens, the infrastructure we built this year will be available if ever needed in future.