This is the second in a series of three posts which discuss recent work to improve type annotations in Sydent, the reference Matrix Identity server. Last time we discussed the motivation for doing this work in the first place: the why. Now I want to talk about the how. How did we add annotations to individual files, and across the project as whole? What common idioms did we learn on the way?
🔗The process of improving coverage
From experience adding typing to Synapse, we decided to annotate one module at a time. We configured a list of files in pyproject.toml which we knew passed mypy's checks. We could run mypy in CI to check that new PRs didn't introduce type problems in modules already covered.
From there, the workflow was
- Choose a new module to annotate. Add it to the list of
files in mypy's configuration.
- Run
mypy. See how many errors you get.
- Choose an error. Fix it. Re-run
mypy.
- Repeat until no errors remaining.
- Submit for review.
There are two parts in there which involve a choice. Being honest, I made those choices unscientifically: I tried to choose the easy tasks to do first. My first target was actually the entire sydent.util subpackage. Probably a bit too large for a first bite! My thinking was that util sounded like something with few dependencies that would have impact across the whole source tree.
Within a given module, I'd try to fix easier errors first: partly for confidence, partly to build up momentum, and partly to get myself familiar with that piece of source code. For example, I'd often start by telling mypy that mylist = [] was actually was a List[str] (rather than the generic List[Any] which it would use otherwise).
Picking and choosing easy targets works fairly well, but sometimes that means you end up fixing an error that's really a symptom of an earlier one. Other times fixing one error, e.g. by giving a return type annotation to a function—would solve a series of other errors throughout the file. Watching the total number of errors mypy reports bob up and down was intriguing!
In retrospect, I think it would be smoother to generate some kind of dependency graph for the package. I'm imagining a DAG where whose vertices are modules, and there's an edge A -> B if A imports from B. The sinks of this DAG (i.e. modules which don't depend on any others in the package) are the ideal place to start: you can get something strictly typechecked there without having to annotate a long chain of dependencies across other files. Another strategy would be to see which modules were the least precise according to mypy's reports—but more on those next time.
🔗You're at the mercy of your dependencies
I think this is my single biggest takeaway from the process of adding annotations to Sydent.
I'll admit the phrasing is melodramatic, but I think it rings true.
Improving coverage boils down to giving the typechecker more information about your program. The more information it has, the more it can check—and the more errors it can spot. (Hopefully this doesn't make typing come across like a pyramid scheme.) If your dependencies aren't typed, mypy can't validate you're correctly providing inputs and correctly consuming outputs. You might have a bigger impact on overall typing coverage by annotating a dependency (directly or via stubs). I have a hunch that bugs are more likely in code that uses an external dependency: we're much more familiar with the details of our own source code compared to that of a third party we trust.
It's worth looking to see if your dependencies have a newer version including type annotations. Failing that, they may have a stub package added to typeshed and published on PyPI. I saw example of both cases when choosing how to configure mypy for Sydent. If some of your dependencies are under your control, consider annotating them—you'll feel the benefits across multiple projects pretty quickly.
🔗Annotations when working with twisted
Twisted is Sydent's biggest dependency, and I certainly felt at its mercy! In particular, it has a few quirks which make it trickier to annotate applications using it. Here's a summary of the work we had to do to get those annotations working.
🔗Partially typed modules and stubs
Early into the process, mypy reported that calling the function twisted.python.log.err was an error. It did so because I was running mypy in --strict mode. We'll talk more about why I did so and what this means next time; for now, it's enough to know that calling a function that isn't fully annotated from within a function that is constitutes an error under strict mode. twisted is partially annotated: many key modules and functions have type annotations, but others don't. I was reluctant to give up on --strict. Instead, I decided to stub the err function myself.
A stub is a cut-down version of a python function, class or module which lives in a .pyi file. All implementation details are removed; only type annotations remain. Stubs are useful when you want to write annotations for code you don't control. The typeshed library is probably the best example: a collection of third party stubs for the standard library, plus some popular third party packages. Microsoft's python-type-stubs is another example. They'd also solve the problem I mentioned at the end of the first part: I could use a stub to teach mypy that IResponse.headers was a Headers object.
Writing a stub for log.err was straightforward, thanks mainly to Twisted's thorough documentation. I chose to write it by hand, rather than use stubgen. I'd heard of the latter, but was reluctant to use it for a few reasons.
- Twisted is a big project with many big files. I didn't want to commit huge stub files for me and my colleagues to maintain.
- The more our stubs cover, the larger the risk of a stub becoming out-of-date with twisted itself. Upstream twisted is the best place for these annotations.
- We only need annotations for the bits of twisted that we're using.
- And, being honest: I wanted the low-level experience of writing stubs, cross-referencing between the source and working how to best capture its type semantics.
I think this decision to write a targeted stub made sense at the time. After all, twisted.python.logging.err is just one simple function! But for the project as a whole, I regret not using stubgen to generate module-level stubs. The reason for this is that a .pyi stub file accounts for an entire module: no more and no less. This means that the stubs I was writing for parts of twisted only covered the functions and classes I'd stubbed. Any existing annotations in the twisted source code would be ignored, along with any types that mypy was able to infer for itself.
I think it would have been more efficient to use stubgen to generate stubs and patch them up, rather than writing them. That would have helped avoid a few cases I encountered where stubbing one function would cause additional typechecking failures (because mypy was no longer examining the twisted source for that file). It would also have meant that I could just faithfully stub Twisted as it is; in practice, I would sometimes hesitate to stub to avoid having to cover another module. sydent.http was the most painful part of the source tree for this: that's where we make the most use of Twisted.
This is a decorator which allows us to write code in the style of async/await without actually using that syntax. (Twisted predates asyncio and the async/await syntax, introduced in Python 3.4 and 3.5 respectively. It was originally released in 2002, back when Python had released version 2.2.) We only use it in one place in Sydent nowadays, but I've seen used across Synapse too. I mention it here because it was a bit fiddly to annotate. Here's its use in Sydent:
@defer.inlineCallbacks
def request(
self,
method: bytes,
uri: bytes,
headers: Optional["Headers"] = None,
bodyProducer: Optional["IBodyProducer"] = None,
) -> Generator["defer.Deferred[Any]", Any, IResponse]:
Here, request is a generator function because its body uses the yield keyword. Yielding allows the function to relinquish control back to twisted's reactor, only for its execution to be resumed asynchronously in the future. The Generator type takes three parameters:
- a
YieldType, Deferred[Any];
- a
SendType, Any; and
- a
ReturnType, IResponse.
Why have I opted to use Any here, when we've seen (and will see) that this limits mypy's ability to run checks? The answer is that we yield two different types within the function. Firstly a routing result:
routing: _RoutingResult
routing = yield defer.ensureDeferred(self._route_matrix_uri(parsed_uri))
and later, the IResponse we go on to return:
res: IResponse
res = yield agent.request(method, uri, headers, bodyProducer)
-
In this example:
-
We yield a value y: Deferred[Any].
-
That will later be resolved by twisted to an x: Any value. Twisted will send that value to request, and the execution continues.
-
This repeats, until we eventually return an IResponse.
I could more correctly annotate the YieldType as Deferred[Union[_RoutingResult, IResponse]] so that the SendType was Union[_RoutingResult, IResponse]. But this would mean we end up having some kind of type check at each yield point: a cast, or a type: ignore, or a runtime isinstance check. It didn't feel like it was worth the boilerplate, especially since I could narrow e.g. res: Any to res: IResponse with minimal effort.
This problem doesn't arise with using the async/await syntax:
async def foo() -> int:
return 1
async def bar() -> None:
x = await foo()
reveal_type(foo())
reveal_type(x)
$ mypy example.py
example.py:6: note: Revealed type is "typing.Coroutine[Any, Any, builtins.int]"
example.py:7: note: Revealed type is "builtins.int*"
Behind the scenes, I think that x = await foo() is really using the same mechanism as the inlineCallbacks approach.
- An
async def function is really a generator function behind the scenes.
- When we
await foo(), we yield the expression foo()
- Then the machinery running our coroutine
c will call c.send(x) to resume execution, where x is the value produced by waiting for foo().
With the await form, mypy knows two things:
- the value
foo() which was yielded should be Awaitable[T], and
- the value
x send to the coroutine should come from awaiting foo(), and therefore be of type T.
Mypy can't assume or enforce these rules for the yield form, which can yield and send whatever it likes. There's no reason why the send type should be related to the yield type. Here's a toy example:
from typing import Any, Dict, Generator
def generator_function() -> Generator[int, str, Dict[str, Any]]:
y: int = 10
x: str = yield y
print("Coroutine was sent", x) # -> Coroutine was sent hello
return {"got": x, "done": True}
coroutine = generator_function()
y = next(coroutine)
try:
coroutine.send("hello")
except StopIteration as e:
return_value = e.value
print(return_value) # -> {'got': 'hello', 'done': True}
All in all, the handling of inlineCallbacks is a situation specific to working with (older?) twisted code. It's still nice to understand what's going on behind the scenes though!
🔗zope.interface.Interface
Twisted makes use of zope's Interface to define a number of abstract interface classes. Speaking personally, I've not seen it used outside twisted, and I think that means it's not supported by much of the typechecking tooling. For example, I've definitely seen PyCharm struggle to realise that it's okay to pass a Response to a function which expects an IResponse! Here's a more complicated example where PyCharm isn't happy with me widening the type LoggingHostnameEndpoint to IStreamClientEndpoint, even though the latter implements the former.
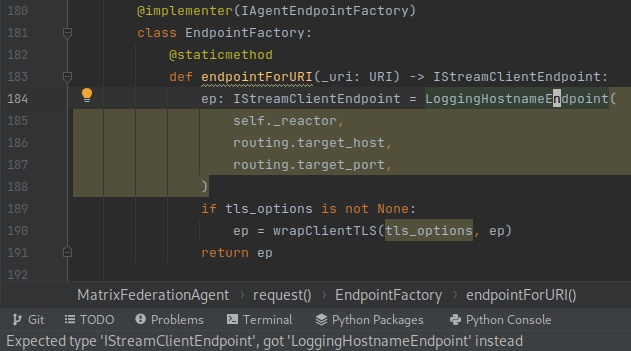
Mypy out of the box doesn't play well with a zope Interface (nor does any other typechecker I tried). Fortunately, the excellent mypy-zope plugin helps here: it teaches mypy that any class like Response which @implements(IResponse) can be passed in place of an IResponse.
🔗Tricks of the trade
At this point I'd like to share a few generic lessons about typing I'd picked up. Nothing ground-breaking here: I think these are all fairly well-known. Hopefully they're the start of a good cheat sheet for annotating—though it pales in comparison to the Mypy cheat sheet.
🔗Annotating decorators
Annotating decorators is fiddly, but it's also vitally important. An unannotated decorator will mask or throw away your decoratee's annotations! The way to write the annotation is best explained by the mypy docs, but briefly: it involves a TypeVar and sometimes a cast too. Here's an example.
from typing import TypeVar, Callable, Any, cast
F = TypeVar("F", bound=Callable[..., Any])
def decorator(input: F) -> F:
def wrapped(*args: Any, **kwargs: Any) -> Any:
print(f"Calling {f.__name__}")
return input_func(*args, **kwargs)
return cast(F, wrapped)
The idea here is
- Use
Callable[..., Any] to describe a generic function with no particular signature.
- Use that as a bound on a type variable
F. At each usage of @decorator, mypy will deduce a more specific version of F, e.g. Callable[[int], str].
- Within that usage of
@decorator, F is fixed to that specific type. We use -> F to express that "we return a function with the same signature as the decoratee".
- Unfortunately, we don't have a good way to tell
mypy that wrapped also has that signature F. We resort to a cast to force mypy to accept this without proof.
This might change in the future, e.g. when ParamSpec is fully understood by mypy.
🔗Prefer object over Any
Both of these are general types for expressing "I don't know anything about this expression". But only the former will undergo static type checks. We want those type checks to guard against bugs accidentally introduced in the future. For instance, imagine a class with an Any attribute.
from typing import Any
import dataclasses
@dataclasses.dataclass
class C:
label: Any
Imagine in the future we add a new method which assumes that label is a string:
def greeting(self) -> str:
return "My name is " + self.label
Mypy will consider this valid, because no type-checking is done on an Any value. It will complain that it can't prove that greeting returns a str, if --warn-return-any is enabled; but putting that aside, it can't identify the call site as a bug. The bug slips through to runtime.
C(123).greeting() # TypeError: can only concatenate str (not "int") to str
Replacing the Any with object does allow mypy to spot the problem.
error: Unsupported operand types for + ("str" and "object") [operator]
🔗# type: ignore and cast sparingly
There's a good chance that mypy knows better than we do, so we should only overrule it if there's no better option. There are two techniques for this. One option is to tell mypy to just silence the error, by appending a # type: ignore comment to the erroneous line. The other is to force it to accept that a certain expression has a given type: that's what cast is for.
I never like using either of these, but sometimes they're the most practical choice. I'd recommend two best practices for their use, however:
- Only ignore a specific error code, e.g.
# type: ignore[assignment]. Those codes can be displayed by passing --show-error-codes to mypy.
- Leave a comment before every
#type: ignore[...] and every cast to justify their correctness. I don't think this is a widely-held practice. I picked it up from the Rust world, where it's encouraged as a way to justify unsafe source code.
🔗There's good stuff in typing
It's worth a read through the module documentation—plenty of things in there I wish I'd known about sooner. There's lots in the toolkit to chose from. Some bits I use fairly often include:
- Protocol: lets you formalise duck typing. To use it, define a class that inherits from
Protocol. Its methods and attributes are all stubs which describe what you require of objects belonging to this type. It's like an abstract base class or interface, but purely at typecheck time.
- Generic: define your own generic types. A bit of a slippery slope to type mania!
- Optional: I use this all the time. It's always good to make your
Nones explicit!
- NewType: I haven't had a chance to use it much. As I understand it, it's a way to define a "strong typedef". For example, we can use it to distinguish lengths from durations, even if they're both represented by a
float at runtime.
I want to call out two parts of typing in particular:
overload is a way to provide extra information about a function depending on how it's called. For instance, consider this function which takes a str or bytes as input and returns its uppercase version.
def upper(x: Union[bytes, str]) -> Union[bytes, str]:
return x.upper()
The problem with this annotation is that we'll have to check at every call site to see if the return value was a bytes or a str object. But we know that uppercasing a str gives us a str, and uppercasing a bytes gives us a bytes. We can use overload to express this.
from typing import overload
@overload
def upper(x: str) -> str: ...
@overload
def upper(x: bytes) -> bytes: ...
def upper(x: Union[bytes, str]) -> Union[bytes, str]:
return x.upper()
The first two @overload definitions are like stubs: they're purely used for their annotations. The actual runtime implementation is specified at the end, undecorated. (NB: this specific example is better expressed without overloads, by using AnyStr.)
I was really impressed to see how mypy could use this overloading information. Here's an example:
from typing import overload, Literal
@overload
def f(x: int) -> Literal[1]: ...
@overload
def f(x: str) -> Literal[2]: ...
def f(x: object) -> int:
if isinstance(x, int):
return 1
elif isinstance(x, str):
return 2
return 3
if f(10) == 2:
print("potato")
We can see that f(10) == 1 and so the equality is always False: we'll never print the word "potato". Mypy can reason through this too, if we ask it nicely.
$ mypy example.py
Success: no issues found in 1 source file
$ mypy --strict-equality --warn-unreachable example.py
example.py:16: error: Non-overlapping equality check (left operand type: "Literal[1]", right operand type: "Literal[2]")
example.py:17: error: Statement is unreachable
Found 2 errors in 1 file (checked 1 source file)
I mentioned this in last week's post) when talking about the missing await bug.
Subclassing from TypedDict allows us to define a new type whose values are dictionaries with
- a fixed set of keys (some mandatory, some not), and
- a fixed type for each key's value.
PEP 589 can best describe the motivation, but in short: there's a lot of source code out there that passes dictionaries around. TypedDict is a way to gradually add typechecking to that code, without having to refactor it to use e.g. a dataclass or a NamedTuple. Let's have a quick example.
from typing import List, TypedDict
class Person(TypedDict):
full_name: str
nicknames: List[str]
age: int
p: Person = {
"full_name": "David Matthew Robertson",
"nicknames": ["dmr"],
"age": 29,
}
Mypy will detect if you delete or omit a required key, or if you insert a key that's not part of the type.
# error: Key "age" of TypedDict "Person" cannot be deleted
del p["age"]
# error: Missing keys ("full_name", "nicknames", "age") for TypedDict "Person"
p2: Person = {}
# error: TypedDict "Person" has no key "eye_colour"
p["eye_colour"] = "brown"
TypedDict is a useful tool, but there are a few important gotchas to be aware of. In my view, these are all minor and worth putting up with, to benefit from the extra type information that a TypedDict provides. Let's take a look.
🔗TypedDict is incompatible with Dict
This one surprised me at first. Why can't I pass my TypedDict to a function that accepts a generic dictionary?
import json
from typing import Dict, TypedDict
class Foo(TypedDict):
bar: str
def print_size(d: Dict[object, object]) -> None:
print(len(d))
f: Foo = {"bar": "baz"}
# error: Argument 1 to "print_size" has incompatible type "Foo"; expected "Dict[object, object]"
print_size(f)
The answer is that it wouldn't be type-safe! For all we know, the function print_size might mutate its argument d. It might add a key, remove a key, or change the type of a value. Each of those would break the contract that TypedDict is supposed to enforce, so mypy is correct to flag this as an error. This GitHub issue has more discussion.
There are few workarounds for this kind of problem.
- The function might be able to accept a
TypedDict directly.
- The function could accept a
Mapping instead of a Dict. This is type-safe because the Mapping type does not offer mutating methods such as pop, __setitem__, __del__; but it only works if the function does not mutate the dictionary.
- A more drastic approach would discard the
TypedDict information with a cast to Dict[str, object] or similar. If so, I'd strongly recommend a comment explaining why the cast is correct and safe.
🔗Mixing mandatory and required fields
Secondly, defining a TypedDict with a mixture of optional and required keys is a little fiddly. All keys can be made optional by passing total=False in the class definition. To have some keys optional and others mandatory, we have to make two TypedDicts. Say for instance we wanted to allow a potentially-missing favourite_colour field to Person. We can't add an annotation favourite_colour: Optional[str] to the first class body. That's optional in a different sense: it would mean that favourite_colour is a mandatory field which is allowed to be None. Instead, we apply total=False to a subclass:
from typing import List, TypedDict
class _PersonRequired(TypedDict):
full_name: str
nicknames: List[str]
age: int
class Person(_PersonRequired, total=False):
favourite_colour: str
This means that a valid Person dictionary may have no favourite_colour key. If it is present, it must be a str.
The syntax is unfortunately a little clunky. PEP 655 acknowledges this and proposes an alternative.
🔗TypedDict is typecheck-time only
One final note: a TypedDict does no validation or conversion whatsoever. If mypy can't know the keys and values a dictionary will have a typecheck-time, you'll need to validate it by hand at runtime. We see this a lot because when deserialising json objects into a dictionary. Here's an example.
import json
from typing import TypedDict
class Foo(TypedDict):
bar: str
# note: Revealed type is "Any"
reveal_type(json.loads("{}"))
# no error. mypy can't do analysis on Any.
f: Foo = json.loads("{}")
🔗Next time
This covers a lot of the machinery and the day-to-day process of annotating Sydent. The last part of this series will give us a chance to quantify our efforts and reflect on the wider typing ecosystem.
Many thanks for reading! If you've got any corrections, comments or queries, I'm available on Matrix at @dmrobertson:matrix.org.
 Category Atom Feed
Category Atom Feed